Tabular Models详解
[TOC]
表格处理
条件替换
xs.loc[xs['YearMade']<1900, 'YearMade'] = 1950
可以把所有符合条件的值都换成1950。
Pandas使用小窍门
pandas使用示例一:类别转字符串
idxs = tensor([7, 8, 7, ..., 8, 1, 5])
dls.vocab = ['bacterial_leaf_blight', 'bacterial_leaf_streak', 'bacterial_panicle_blight', 'blast', 'brown_spot', 'dead_heart', 'downy_mildew', 'hispa', 'normal', 'tungro']
如何得到最终的列表,所有元素都是类别对应的字符串呢?
mapping = dict(enumerate(dls.vocab))
results = pd.Series(idxs.numpy(), name="idxs").map(mapping)
submission['label'] = results
submission.to_csv('subm.csv', index=False)
然后就可以了!
当然还有第二种更简单的解决方案。
vocab = np.array(learn.dls.vocab)
results = pd.Series(vocab[idxs], name="idxs")
pandas使用示例二:loc的使用

然后我们如何通过图片的名称来索引出对应的variety呢?答案是使用dataframe的loc方法:
df.loc['100330.jpg', 'variety'] # 'ADT45'
pandas使用示例三:merge
我们有一个Dataframe叫做ratings,列分别为:user, movie, rating, timestamp。其中movie对应的都是id。
正好我们还有一个Dataframe叫做movies,有两列,分别为movie和title。
于是我们就可以使用
ratings = ratings.merge(movies)
来获得合并后的表格,无缝衔接了每个电影id对应的名称!

第一个阶段:前期数据处理
写在前面:我只能说这一部分的内容因为内容太多,很多地方我都是用的copy+paste代码,很有可能以后还要回来补充。
我们以经典数据集Titanic为例。为了保证这样的笔记对未来的项目有指导意义,我就把从数据处理、训练之类的全部代码都放出详细解释,因为之后需要这样的Tabular Model的情况还是很多的。
我们先用fastkaggle下载了titanic数据集,并且用df = pd.read_csv(path/'train.csv', low_memory=False)来把训练数据读入我们的Dataframe。注意,low_memory=False很重要,可以保证pandas对数据类型判断的准确性。
拿到表格之后,我们该干什么?
面对表格数据,我们一般采取如下步骤:
第一种路径:直接操作Dataframe和进行Feature Engineering
第一步,找有没有缺失的数据,使用df.isna().sum()。这会返回给我们一个Series对象,里面有各列的空缺数据的个数。

缺失的数据如果不填上,是无法被神经网络或者随机森林处理的。那么怎么把这些空缺补上呢?
fastai有对应的函数来加速这一过程,但如果手头没有fastai可用,可以使用传统的pandas方法,写在下面:
用df.mode()可以帮我们找到每一列的众数。但是众数可能会有好多个,因此它的返回值仍然是一个Dataframe。所以我们取df.mode().iloc[0],也就是这个新的Dataframe的第一行,作为用来填充缺失值的Series。
用df.fillna(modes, inplace=True)即可。为了检验效果,可以再运行一遍df.isna().sum()。不仅对于训练集,对于验证集,最好也要这样做一遍预防数据缺失的工作。可能会有不同的列出现数据缺失,这里自动填充会比手动填充更加具有灵活性。
第二步,分析数据。df.describe(include=(np.number))可以给我们展示dataframe的数值总览,很有用。注意那些平均数与中位数相差很多的连续变量。可能需要取对数来让分布更加均匀,方便神经网络的训练。在这里,Fare一列就是我们重点的怀疑对象,平均数远大于中位数!
所以我们使用df['Fare'].hist()绘制直方图,直观感受Fare的分布情况:

看来确实需要进行额外的处理,使用df['LogFare'] = np.log(df['Fare']+1)就可以取对数了!另外附上df.describe()的结果:

还需要检查的一点:这些都是连续变量吗?显然Pclass、Parch并不是,Survived也不是,但由于这是我们要预测的对象,最终会特殊处理。
想要看Pclass到底都包含哪些值,可以使用sorted(df.Pclass.unique())来检索。
我们再看看pandas认为的categorical variables都是哪些,用df.describe(include=[object])即可。
第三步,我们转换categorical variables。这一步比较重要,有很多内容,所以提升成了标题级别。
df = pd.get_dummies(df, columns=["Sex","Pclass","Embarked"])
df.columns
# Index(['PassengerId', 'Survived', 'Name', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'LogFare', 'Sex_female', 'Sex_male', 'Pclass_1', 'Pclass_2', 'Pclass_3', 'Embarked_C', 'Embarked_Q', 'Embarked_S'], dtype='object')
为什么不包含所有的非连续变量呢?因为其他的变量可能对最终结果都没有影响,我们只关注看上去最有可能反映survive状况的。
当然,get_dummies方法对于神经网络来说,最为有用。如果目标是创建随机森林,那就没有必要创建这么多新的列,而是采用下面的方法:
df['Embarked'] = pd.Categorical(df.Embarked)
df['Sex'] = pd.Categorical(df.Sex)
Categorical的本质是把这些变量的文字转化成对应的数字代码。这些代码可以通过df.Sex.cat.codes.head()获取,但我们也用不到!
| 对于这样的categorical variables还有一种可能,最好特殊处理来达到最佳效果:它们是用字符串表达的,但意思存在着天然的大小关系。比如,在[Blue Book for Bulldozers | Kaggle](https://www.kaggle.com/c/bluebook-for-bulldozers)这个比赛的数据集中,我们发现,df['ProductSize'].unique()对应的数值是[nan, 'Medium', 'Small', 'Large / Medium', 'Mini', 'Large', 'Compact'],它们确实是可以被进一步排序的,而不是仅仅有一个简单的类别代码! |
因此我们使用
sizes = 'Large','Large / Medium','Medium','Small','Mini','Compact'
df['ProductSize'] = df['ProductSize'].astype('category')
df['ProductSize'].cat.set_categories(sizes, ordered=True)
来规定这一顺序。当然,这三行代码本身也是有很多玄机的。
.astype('category')和pd.Categorical有微妙的区别。但是创建的数据类型是相同的。- 我们获得更多信息的方式可以是通过
df['ProductSize'].cat.categories来获得完整的文字列表,形如['Compact', 'Large', 'Large / Medium', 'Medium', 'Mini', 'Small']。
第四步,处理日期。
df = add_datepart(df, 'saledate')
然后对应的列就会变成:
'saleYear saleMonth saleWeek saleDay saleDayofweek saleDayofyear saleIs_month_end saleIs_month_start saleIs_quarter_end saleIs_quarter_start saleIs_year_end saleIs_year_start saleElapsed'
最后,增加特征。
以下是为了增强模型表现而做的处理:
def add_features(df):
df['LogFare'] = np.log1p(df['Fare'])
df['Deck'] = df.Cabin.str[0].map(dict(A="ABC", B="ABC", C="ABC", D="DE", E="DE", F="FG", G="FG"))
df['Family'] = df.SibSp+df.Parch
df['Alone'] = df.Family==1
df['TicketFreq'] = df.groupby('Ticket')['Ticket'].transform('count')
df['Title'] = df.Name.str.split(', ', expand=True)[1].str.split('.', expand=True)[0]
df['Title'] = df.Title.map(dict(Mr="Mr",Miss="Miss",Mrs="Mrs",Master="Master")).value_counts(dropna=False)
add_features(df)
我们想让模型从表格数据中得到尽可能多的信息。
log1p正是我们之前使用的加1再取对数的方法。- 对于
Deck的分析可能需要真的去搜集关于titanic的资料,这里不用特别在意。
Groupby的使用
这里必须列一个groupby的小专题。这玩意怎么理解?
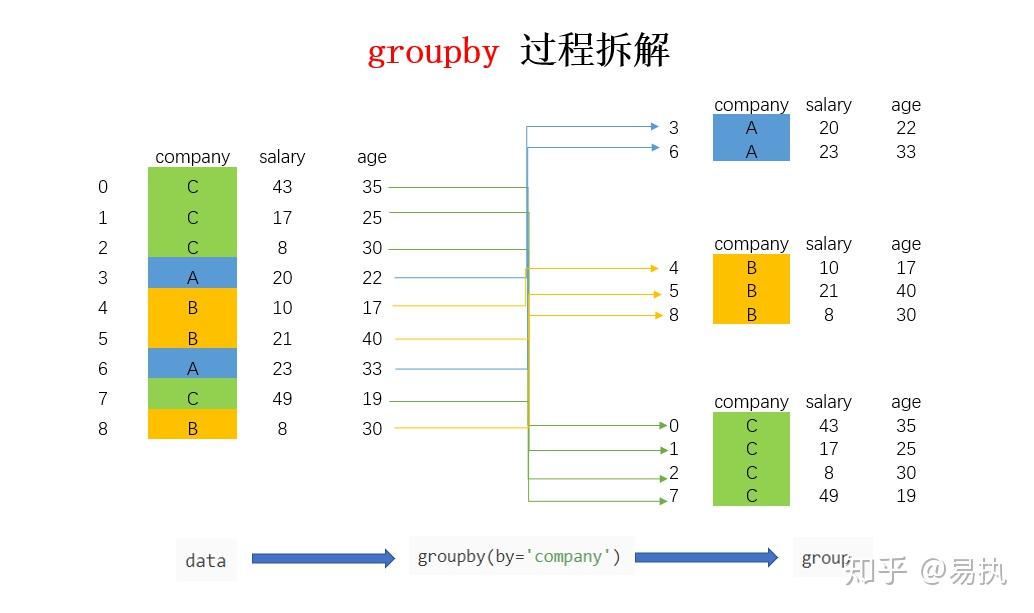
这体现了数据分析中拆分-应用-聚合的思想。
df.groupby('Ticket')体现了拆分。因为不同的人可以共享同一个ticket,所以会按照不同的船票号码分成许多组。但是这个中间值并不会给我们展示数据,len以下就可以得到有681个独立的ticket。
然后我们关心的是:对于每一个个体,他们手持的船票到底被几个人共同使用?
由于刚才的groupby选择了dataframe中所有的列,我们只需要查看ticket,所以用df.groupby('Ticket')['Ticket']。
但这仍然也只是中间值,没有实际意义。
聚合的地方来了!我们加上transform('count')就可以达到我们的目的!这背后的原理很复杂,还有其他的应用,但这里就不在细讲,之后补充。
批量字符串操作:str.split
df['Title'] = df.Name.str.split(', ', expand=True)[1].str.split('.', expand=True)[0]
这一长串的字符串魔幻操作,怎么理解?
其实直接按照字面意思就可以了。expand=True得到的结果是这样的,切割的内容被分成了两列的dataframe:

然后我们最终获得的title就是['Mr', 'Mrs', 'Miss', 'Master', 'Don', 'Rev', 'Dr', 'Mme', 'Ms', 'Major', 'Lady', 'Sir', 'Mlle', 'Col', 'Capt', 'the Countess','Jonkheer']中的一个。
如果expand=False,那么获得的就是把字符串变成列表。
第二种路径:直接使用TabularPandas
当然,前面的操作步骤有些也是必要的。
fastai的cont_cat_split方法
在bluebook for bulldozers的比赛数据集中,数据处理环节有这样一行代码:
cont,cat = cont_cat_split(df, 1, dep_var=['SalePrice'])
为什么max_card就是1呢?注意这个cont_cat_split背后的原理:一个变量被认定为是连续的数值变量,需要满足它既是整数类型,且独立的值的数量大于max_card。这里设为一,就是默认所有数值组成的变量都是连续的。其实随机森林也不是特别挑剔这些要求,这样做就很方便!
创建splits
我们需要分出训练集和验证集。
cond = (df.saleYear<2011) | (df.saleMonth<10)
train_idx = np.where( cond)[0]
valid_idx = np.where(~cond)[0]
splits = (list(train_idx),list(valid_idx))
可能的一个例子长这样,用到了np.where,返回符合条件的数组下标。
splits = RandomSplitter(seed=42)
dls = TabularPandas(
df, splits=splits,
procs = [Categorify, FillMissing, Normalize],
cat_names=["Sex","Pclass","Embarked","Deck", "Title"],
cont_names=['Age', 'SibSp', 'Parch', 'LogFare', 'Alone', 'TicketFreq', 'Family'],
y_names="Survived", y_block = CategoryBlock(),
).dataloaders(path=".")
- 正如之前提到过的,splits其实是两个包含对应数据索引的列表。前一个是训练集,后一个是测试集。
- procs的作用是:就很万能,放进去就行了。
Turn strings into categories, fill missing values in numeric columns with the median, normalise all numeric columns.
- 然后规定一下哪些变量当作类别处理,那些当作连续的处理。
- 如果用于分类,需要指定
y_block=CategoryBlock(),如果用于regression,则不需要指定。
既然有了dataloaders,那直接创建learner就行了!
learn = tabular_learner(dls, metrics=accuracy, layers=[10,10])
learn.lr_find(suggest_funcs=(slide, valley))
learn.fit(16, lr=0.03)
做了这么多准备工作,先保存一下处理之后的数据,直接path.save:
save_pickle(path/'to.pkl',to)
to = load_pickle(path/'to.pkl')
这里的to是经过处理之后的TabularPandas对象。
第二个阶段:创建决策树和随机森林
用scikit-learn创建决策树。(谁说随机森林模型非得用fastai自己家的了?)敲重点,使用graphviz可视化决策树的代码在这里!
from sklearn.tree import DecisionTreeClassifier
m = DecisionTreeClassifier(max_leaf_nodes=4).fit(trn_xs, trn_y)
draw_tree(m, trn_xs, size=10, leaves_parallel=True, precision=2)
如果报错记得python手动加PATH。
还可以有参数min_samples_leaf=50防止树过拟合。m.get_n_leaves()可以获得决策树的叶节点数量,m.predict(xs)可以获得决策树的预测。当然,决策树只是用来演示原理用的,真正用来预测必须是使用随机森林。
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
def rf(xs, y, n_estimators=40, max_samples=200_000,
max_features=0.5, min_samples_leaf=5, **kwargs):
return RandomForestRegressor(n_jobs=-1, n_estimators=n_estimators,
max_samples=max_samples, max_features=max_features,
min_samples_leaf=min_samples_leaf, oob_score=True).fit(xs, y)
m = rf(xs, y);
随机森林的误差函数
无脑,直接粘贴代码:
def r_mse(pred,y): return round(math.sqrt(((pred-y)**2).mean()), 6)
def m_rmse(m, xs, y): return r_mse(m.predict(xs), y)
然后,我们可以通过遍历m.estimators_来单独获取每一个决策树。
第三个阶段:数据分析
检验随机森林过拟合
r_mse(m.oob_prediction_, y)就可以了。测试其Out-Of-Bag-Error。如果out-of-bag误差低于测试集误差,说明有其他因素在导致模型出现误差。
这个oob_prediction_自身返回的应该就是所有树的oob_prediction的平均值,反正这是我理解的。
对某一行数据预测的可信程度
不同决策树之间的分歧越大,对于某一结果的可信程度就越低。通过计算标准差实现。
preds = np.stack([t.predict(valid_xs) for t in m.estimators_])
preds_std = preds.std(0)
注意:preds的形状是(40, 7988),是每个树对验证集每个数据的预测结果。然后使用std(0)是为了让数据在行的方向上坍缩,成1行7988列的怪物,从而获得树在每一个数据上的标准差!
特征重要程度
这玩意大致的计算过程就是:程序遍历每一棵树,看一看不同的split对模型误差的影响,如果降低的多,说明对应的feature越重要。
def rf_feat_importance(m, df):
return pd.DataFrame({'cols':df.columns, 'imp':m.feature_importances_}
).sort_values('imp', ascending=False)
fi = rf_feat_importance(m, xs)
def plot_fi(fi):
return fi.plot('cols', 'imp', 'barh', figsize=(12,7), legend=False)
plot_fi(fi[:30]);

然后我们就可以据此删除不是那么重要的特征来简化模型:
to_keep = fi[fi.imp>0.005].cols
xs_imp = xs[to_keep]
valid_xs_imp = valid_xs[to_keep]
m = rf(xs_imp, y)
删除重复feature
cluster_columns(xs_imp)

寻找不同特征之间的相关性并不需要random forest,只使用一些数据分析的方法即可。
解读这个图的方法是,从右边往左看,如果两个列被合并的越早,它们之间的相关性和重复性就越大,可以考虑去掉其中一个。可是我们也会有一些疑惑:万一去掉之后模型的表现大幅下降怎么办?要不先分别对不同的feature删除一项试一试,如果误差没有明显下降,再真正的把对应的列删除。
而且,我们要找的是删除某列之后的oob_score,越靠近1,说明这个模型预测数据的能力越理想。
def get_oob(df):
m = RandomForestRegressor(n_estimators=40, min_samples_leaf=15,
max_samples=50000, max_features=0.5, n_jobs=-1, oob_score=True)
m.fit(df, y)
return m.oob_score_
get_oob(xs_imp) # 这是不删除任何重复特征的版本
{c:get_oob(xs_imp.drop(c, axis=1)) for c in (
'saleYear', 'saleElapsed', 'ProductGroupDesc','ProductGroup',
'fiModelDesc', 'fiBaseModel',
'Hydraulics_Flow','Grouser_Tracks', 'Coupler_System')}
# 根据score判断下面四个列是要删去的
to_drop = ['saleYear', 'ProductGroupDesc', 'fiBaseModel', 'Grouser_Tracks']
get_oob(xs_imp.drop(to_drop, axis=1))
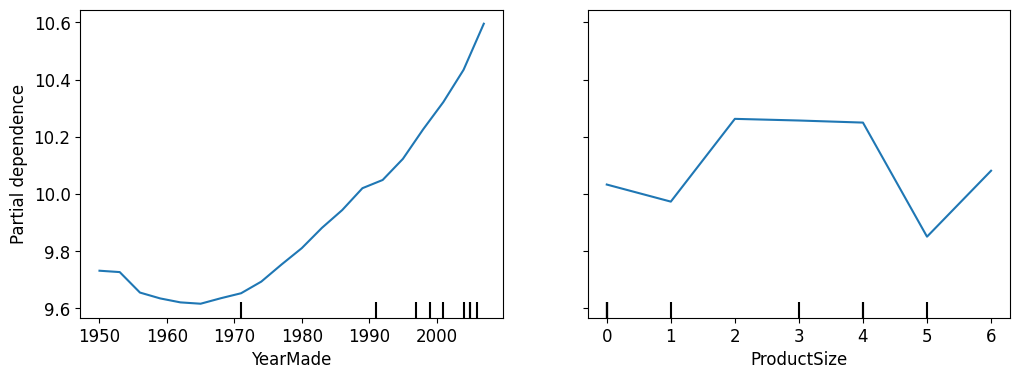
分离出某变量对最终结果的影响
from sklearn.inspection import PartialDependenceDisplay
fig,ax = plt.subplots(figsize=(12, 4))
PartialDependenceDisplay.from_estimator(m, valid_xs_final, ['YearMade','ProductSize'],
grid_resolution=20, ax=ax);
追踪某一行各变量的影响
from treeinterpreter import treeinterpreter
from waterfall_chart import plot as waterfall
row = valid_xs_final.iloc[:5]
prediction,bias,contributions = treeinterpreter.predict(m, row.values)
waterfall(valid_xs_final.columns, contributions[0], threshold=0.08,
rotation_value=45,formatting='{:,.3f}');

外推缺陷
随机森林的一个缺陷就是,如果面对和训练集差异很大的数据,泛化能力会严重下降。为了防止验证集中出现过多与训练集不一样的数据点,可以创建一个随机森林找出那些在两个数据集中差异最大的feature,看看能不能将其去除。这种方法的本质是,建立一个新的随机森林,让它预测先前的数据中的每一行属于训练集还是验证集。然后我们检查去除这些特征后的随机森林是否会出现更大的误差,根据所给数据,去除SalesID和MachineID会降低模型的预测误差,从而提升表现!
df_dom = pd.concat([xs_final, valid_xs_final])
is_valid = np.array([0]*len(xs_final) + [1]*len(valid_xs_final))
m = rf(df_dom, is_valid)
rf_feat_importance(m, df_dom)[:6]
# 找到前几名,其中saleElapsed是直接编码时间的,去除之后误差增大,所以不能这么干
m = rf(xs_final, y)
print('orig', m_rmse(m, valid_xs_final, valid_y))
for c in ('SalesID','saleElapsed','MachineID'):
m = rf(xs_final.drop(c,axis=1), y)
print(c, m_rmse(m, valid_xs_final.drop(c,axis=1), valid_y))
# 输出:
orig 0.232847
SalesID 0.229677
saleElapsed 0.235775
MachineID 0.231492
- 我们还可以去除数据集中过于老旧的数据,提升随机森林的泛化能力。
filt = xs['saleYear']>2004
xs_filt = xs_final_time[filt]
y_filt = y[filt]
m = rf(xs_filt, y_filt)
m_rmse(m, xs_filt, y_filt), m_rmse(m, valid_xs_time, valid_y)
第四个阶段:使用神经网络
因为要使用神经网络,在数据的预处理上,要求就比random forest少了很多。这些都是我们先前已经做过的处理。
df_nn = pd.read_csv(path/'TrainAndValid.csv', low_memory=False)
df_nn['ProductSize'] = df_nn['ProductSize'].astype('category')
df_nn['ProductSize'].cat.set_categories(sizes, ordered=True, inplace=True)
df_nn[dep_var] = np.log(df_nn[dep_var])
df_nn = add_datepart(df_nn, 'saledate')
df_nn_final = df_nn[list(xs_final_time.columns) + [‘SalePrice']]
然后我们看一下哪些是categorical的变量:
cont_nn,cat_nn = cont_cat_split(df_nn_final, max_card=9000, dep_var=dep_var)
df_nn_final[cat_nn].nunique()
# 输出:
YearMade 73
Coupler_System 2
ProductSize 6
fiProductClassDesc 74
ModelID 5281
fiSecondaryDesc 177
fiModelDescriptor 140
fiModelDesc 5059
Hydraulics_Flow 3
Enclosure 6
Drive_System 4
Hydraulics 12
ProductGroup 6
Tire_Size 17
dtype: int64
很显然,我们并不想让最终的程序有太多的列需要考虑。能不能去掉fiModelDesc呢?
xs_filt2 = xs_filt.drop('fiModelDesc', axis=1)
valid_xs_time2 = valid_xs_time.drop('fiModelDesc', axis=1)
m2 = rf(xs_filt2, y_filt)
m_rmse(m2, xs_filt2, y_filt), m_rmse(m2, valid_xs_time2, valid_y)
cat_nn.remove('fiModelDesc')
反正去掉之后对random forest的影响不是很大。我又试了一下,好像去不去掉对于神经网络并没有影响。反正方法先放在这里。
接下来我们建立Dataloaders和Learner:
procs_nn = [Categorify, FillMissing, Normalize]
to_nn = TabularPandas(df_nn_final, procs_nn, cat_nn, cont_nn,
splits=splits, y_names=dep_var)
dls = to_nn.dataloaders(1024)
learn = tabular_learner(dls, y_range=(8,12), layers=[500,250],
n_out=1, loss_func=F.mse_loss)
learn.lr_find()
learn.fit_one_cycle(5, 1e-2)
preds,targs = learn.get_preds()
r_mse(preds,targs)
此时的结果已经好于刚才的随机森林。但是我们可以把二者的结果结合,进一步降低误差:
rf_preds = m.predict(valid_xs_time)
ens_preds = (to_np(preds.squeeze()) + rf_preds) /2
r_mse(ens_preds,valid_y)
会发现这是我们迄今为止得到的最好的结果!