深度强化学习 理论笔记
[TOC]
这本来是我学习Grokking Deep Reinforcement Learning这本书时所做的笔记,但是现在重新看来,发现并没有很好的结构和体系。如今我在学DeepRL BootCamp这个系列的课程,里面的内容更加成体系,所以我打算重新写一份。我先把旧版的笔记发到博客上纪念一下。
蒙特卡罗方法:估计函数期望值
采样,计算$(f(x_1)+f(x_2)+…+f(x_n))/n$即可。
编程优化:采用Robbins-Monro算法。递推实现。
令$q_0=0$,依次计算
$q_t = (1-\frac{1}{t})\cdot q_{t-1}+\frac{1}{t}\cdot f(x_t)$
到最后就可以得到这个函数的期望值。这和以后的Q算法很像,到时候再说。
深度Q学习
\[\Large Q(s_t, a_t; W) \approx r_t+\gamma\cdot Q(s_{t+1}, a_{t+1}; W)\]因为Q函数是对不同时刻动作价值的估计,而把Q换成U,那么确实会变成等式。所以这个约等于是成立的。
Frozen Lake:给定马尔科夫条件寻找最佳策略

强化学习的过程当然要从易到难,我们先从一个最基本的例子开始讲起,再逐渐补充更加复杂的方法。
这是一个简单的Frozen Lake环境,小人可以上下左右移动,但是他做出决策之后,只有三分之一的概率能够达到目的,剩下的情况则是向两边滑动。
如果我们已经知道从每一个格走到其他格子的概率分布,那么我们能不能通过某种算法,找到小人从起点走到终点的路径方案的最优解呢?也就是,小人如何决策自己在每个格子上向哪个方向走,来增大得到奖励的期望值?很显然,我们最终的策略,就是一个表格,记录着小人在每个格子上应该做出的决策。如果想要优化一个策略,必须先有办法来评估它的好坏,这就是我们马上要做的:估计出一个状态价值函数。这个函数接受某一个状态作为输入,输出在给定策略下,最终获得回报的期望值。
1. 已知马尔科夫链,得到价值函数
我们采用下面的式子来估计状态价值函数,它看上去复杂,其实表达的是一个很简单的意思。 \(\Large v_{k+1} (s)= \sum_{a}\pi (a|s) \sum _ {s',r} p(s',r|s,a)[r+ \gamma v_ {k} (s')]\) 我们计算一个状态的价值,就需要对它之后能够到达的所有状态、以及对应的概率进行枚举,相乘之后得到最后的期望。
因为我们采用的策略不存在不确定性,所以第一个求和符号对应必须是1,实际用到的公式被大大简化了!
然后我们看做出了某一个动作之后,期望得到的奖励(这里还要使用期望值,因为环境对于这个动作的反应也存在随机性)。我们枚举之后可能出现的状态,让每个状态出现的概率乘以对应状态下的期望奖励——是一个递推问题!
关键是,我们要求这个状态的价值函数,可是这依赖于其他状态的价值,反过来又会产生依赖……所以怎么求解呢?不用着急,我们先把所有的状态的价值初始化成随机数,然后一次一次地迭代,直到整个函数的取值收敛,也就是各个状态的价值不再更新。
def policy_evaluation(pi, P, gamma=1.0, theta=1e-10):
prev_V = np.random.random(len(P)) # 16 states in frozen lake env
while True:
V = np.zeros(len(P)) # will be updated shortly after
for s in range(len(P)):
for prob, next_state, reward, done in P[s][pi[s]]:
V[s] += prob * (reward + gamma * prev_V[next_state] * (not done))
if np.max(np.abs(prev_V - V)) < theta:
break
prev_V = V.copy()
return V
有意思的是,我们是通过迭代近似寻找一组多元线性方程组的解。和神经网络不同,我们并没有进行梯度下降,就降低了拟合的误差,很有趣!而且我们的得到的解通常是唯一的。
2. 已知价值函数,求最优化策略
\(\Large\pi '(s)=arg\max_{a} \sum _{s', r} {p(s',r|s,a)} [r+ \gamma v_ {\pi } (s')]\) 然后我们使用上面这个式子来寻找最佳策略!
def policy_improvement(V, P, gamma=1.0):
Q = np.zeros((len(P), len(P[0])), dtype=np.float64)
# the zeros will be filled out later
for s in range(len(P)):
for a in range(len(P[s])): # for every action in every state
for prob, next_state, reward, done in P[s][a]: # only iterates once
Q[s][a] += prob * (reward + gamma * V[next_state] * (not done))
new_pi = dict(zip(range(len(P)), np.argmax(Q, axis=1)))
return new_pi
这里再点一个点,那就是*(not done)的作用是防止重复计算,导致函数爆炸。
一般来说,frozen lake这种简单的问题,迭代一次就可以找到最优解。
3. 已知马尔科夫链,直接求最优价值函数和最优化策略(Value Iteration)
其实对于FrozenLake这个环境来说,想求出最优价值函数是非常简单的。如果Horizon=0,那么智能体便没有可以执行的动作,所有状态的奖励都会是零,也就是说 \(\Large\begin{align*} V_0^*(s) &= 0 \quad \forall s \end{align*}\) 那么,如果Horizon=1就有 \(\Large \begin{align*} V_1^*(s) &= \max_{a} \sum_{s'} P(s' \mid s,a)\bigl(R(s,a,s') + \gamma V_0^*(s')\bigr) \end{align*}\) 上面的这个式子是完全可以计算的!以此类推,我们一直套用这个公式,就得到了最优的价值函数。下面是完整的迭代算法: \(\large\begin{align*} &\text{Start with}\quad V_0^*(s)=0\quad\text{for all }s.\\ &\text{For }k=1,\dots,H:\\ &\quad\text{For all states }s\in\mathcal{S}:\\ &\qquad V_k^*(s)\leftarrow \max_{a}\sum_{s'} P(s'\mid s,a)\Big(R(s,a,s')+\gamma V_{k-1}^*(s')\Big),\\ &\qquad \pi_k^*(s)\leftarrow \arg\max_{a}\sum_{s'} P(s'\mid s,a)\Big(R(s,a,s')+\gamma V_{k-1}^*(s')\Big). \end{align*}\) 最后再解释一个理论问题,为什么随着H增大到一定程度之后,我们就相信状态价值函数在各个点的值会收敛?看下面的等式。 \(\large \begin{align*} \gamma^{H+1}R(s_{H+1})+\gamma^{H+2}R(s_{H+2})+\dots \le \gamma^{H+1}R_{\max}+\gamma^{H+2}R_{\max}+\dots = \frac{\gamma^{H+1}}{1-\gamma}R_{\max} \end{align*}\) 如果我们前H步都按照最优的方案走,那么最终再获得的总回报也会有上限,而且随着H的增大,这个新增回报的上限趋近于零,所以进行H步迭代随着H的增大,得到的状态价值函数是可以逼近进行无穷多步的状态价值函数。除此之外,我们还宣称,不管前面怎么初始化状态价值函数,它最终都会收敛到一套正确的值上。下面给出正式的证明。
我们先定义$|U|$是矩阵U里面绝对值最大的元素。假设我们有两套状态价值函数的估计值U和V,经过一步更新之后,我们得到了TU和TV。现在我们计算TU-TV: \(\large (TU)(s) = \max_a \Big[ R(s,a) + \gamma \sum_{s'} P(s'|s,a)\, U(s') \Big]\) 根据最大值不等式$|\max_a f(a) - \max_a g(a)| \leq \max_a |f(a) - g(a)|$,对两式相减有 \(\large (TU)(s)-(TV)(s)\leq \max_a\; \gamma \Big|\sum_{s'} P(s'|s,a)\big[U(s') - V(s')\big]\Big|\) 利用绝对值不等式进一步缩放 \(\large \leq \max_a\; \gamma \sum_{s'} P(s'|s,a)\,|U(s') - V(s')|\) 然后我们发现,$|U(s’) - V(s’)|$对于每一个状态都会小于等于$|U-V|$,所以我们直接进行替换,得到对于每一个状态,两个状态价值函数的估计的差距都会至少是原来的$\gamma$倍。所以说,下面的不等式成立: \(\large \|TU-TV\| \leq \gamma \|U-V\|\) 有了这个定理,我们如果把U、V换成同一个状态价值函数在一次迭代时的前后版本,那么有 \(\large \|V_{i+1} - V^*\| \leq \gamma\epsilon + \gamma^2\epsilon + \gamma^3\epsilon + \cdots = \frac{\gamma\epsilon}{1-\gamma}\) 这基本上就证明了随机初始化状态价值函数也可以收敛,而且在更新足够小的时候,里面的每个值离最终值的差距也会足够小!
迭代算法转换成代码就成了下面的样子。我原来做笔记的时候完全不知道上面这些数学公式,根深蒂固的以为状态价值函数和动作价值函数都应该随机初始化,现在想想真是一点也不靠谱。
def value_iteration(P, gamma=1.0, theta=1e-10):
V = np.zeros(len(P))
for i in range(10):
Q = np.zeros((len(P), len(P[0])))
for s in range(len(P)):
for a in range(len(P[s])):
for prob, next_state, reward, done in P[s][a]:
Q[s][a] += prob * (reward + gamma * V[next_state] * (not done))
if np.max(np.abs(V - np.max(Q, axis=1))) < theta:
break
V = np.max(Q, axis=1)
pi = dict(zip(range(len(P)), np.argmax(Q, axis=1)))
return V, pi
另外,我改动了pi的形式:原来的程序是通过lambda返回函数,但是会出现什么无法序列化的问题。我就直接把它改成字典了。 \(\Large \mathcal{T} = \sum_{e=1}^{E} \mathbb{E} \left[ v_* - q_*\left(A_e\right) \right]\) 这是总regret的计算方式,是一个agent在做出一系列选择的过程中,获得总reward与预期最高总reward的偏差。
从此之后,我们就不再知道状态转移概率之类的信息,但是我们仍然能够想办法让智能体找到最优的策略!
附加内容:Explore与Exploit的平衡
强化学习的核心在于估计。我们会让智能体通过大量的行动和实验来估计出一个越来越准确的状态价值函数,但是有一个行为策略上的分歧:因为最终的目标是让智能体得到更多的奖励和回报,那么智能体应该在训练过程中根据什么程度,按照自己的估计来走,还是多采取一些之前没有试过的选择,“探索”它会不会是更好的?基本的规律是,开始我们鼓励智能体做出一些随机的行为来探索环境,快速建立一个比较准确的对动作和状态价值函数的估计,之后再利用自己的估计最大化收益,减小随机行动的次数。
为了达成这个目的,我们有下面几个方法可以使用,但是其中ε-decay方法最为常见。
- ε decay方法:智能体采取一定概率随机行动,而且随着训练过程的进行,这样“探索”的概率逐渐减小。既可以线性减小,也可以指数减小。
- softmax方法:选择不同action的概率分布和softmax值相对应。
- optimistic方法:先把Q函数的值设为远高于预期,每次的exploit都会降低预期,使得Q函数最终的估计逼近正常值。但是这样的方法比较少见,因为超参数难以调整,比如说Q函数的初始值应该设成多少?降低预期的时候,每次又应该更新多少?如果不知道环境对应的奖励函数,那么盲目设置初始值就会产生灾难性的后果。代码如下:
def optimistic_initialization(env, optimistic_estimate=1.0, initial_count=100, n_episodes=5000):
Q = np.full((env.action_space.n), optimistic_estimate, dtype=np.float64)
N = np.full((env.action_space.n), initial_count, dtype=np.float64)
Qe = np.empty((n_episodes, env.action_space.n))
returns = np.empty(n_episodes)
actions = np.empty(n_episodes, dtype=int)
for e in range(n_episodes):
action = np.argmax(Q)
_, reward, _, _ = env.step(action)
N[action] += 1
Q[action] = Q[action] + (reward - Q[action])/N[action] # average reward for actions
Qe[e] = Q
returns[e] = reward
actions[e] = action
return name, returns, Qe, actions
- Upper Confidence Bound方法:我们应当鼓励程序尝试那些自己更不熟悉的选择,即高不确定性的动作具有优先性。在所有动作中,某一动作数量的占比越小,它具有的优先级就越大,越应该被马上尝试。我列出了代码中的关键部分:
U = np.sqrt(c * np.log(e)/N)
action = np.argmax(Q + U)
- Thompson sampling:我们不仅仅记录Q的估计值,而且把它当成一个正态概率密度函数的观测值。每一个状态下的每一个行动都有一个对应的概率分布,它的期望值就是Q值的估计,标准差则是对不确定性的估计。这里有两个超参数需要调节。
samples = np.random.normal(loc=Q, scale=alpha/(np.sqrt(N) + beta))
action = np.argmax(samples)
4. 不知道马尔科夫链,估计价值函数
从现在起,我们就无法再获取环境的各种状态转移概率。但是我们仍然可以有算法用来近似!
0. 蒙特卡罗方法:
- 生成运动路径
- 遍历回报
- 逐个状态修改
def generate_trajectory(pi, env, max_steps=20):
done, trajectory = False, []
while not done:
state, _ = env.reset()
for t in range(max_steps):
action = pi[state]
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
experience = (state, action, reward, next_state, done)
trajectory.append(experience)
if done:
break
state = next_state
if not done:
trajectory = []
return np.array(trajectory)
def decay_schedule(init_value, min_value, decay_ratio, max_steps):
decay_steps = int(max_steps * decay_ratio)
values = np.logspace(np.log10(min_value), np.log10(init_value), decay_steps)[::-1]
values = np.pad(values, (0, max_steps-decay_steps), 'edge')
return values
我们先用generate_trajectory函数生成一个完整的智能体走过的路径。代码很简单,就是根据策略随机生成一个在20步内智能体走过的路径。如果还没有走完,那就抛弃这个路径重新生成。最后返回一个数组,有不到20行和5列。
然后我们引入一个新函数decay_schedule,负责生成按指数规模衰减的学习率之类的,[::-1]是负责翻转序列。最后的np.pad是为了填充最后的values,第二个参数是指定左边和右边都填充多少,并且edge的意思是按照数组最边上的元素填充。
def mc_prediction(pi, env, gamma=0.98, init_alpha=0.7, min_alpha=0.005, alpha_decay_ratio=0.3, n_episodes=5000, max_steps=100, first_visit=True):
nS = env.observation_space.n
discounts = np.geomspace(1, pow(gamma, max_steps), max_steps, endpoint=False)
alphas = decay_schedule(init_alpha, min_alpha, alpha_decay_ratio, n_episodes)
V = np.zeros(nS)
V_rec = np.zeros((n_episodes, nS))
for e in range(n_episodes):
trajectory = generate_trajectory(pi, env, max_steps)
visited = np.zeros(nS, dtype=np.bool)
# looping through experience
for t, (state, _, _, _, _) in enumerate(trajectory):
if visited[state] and first_visit:
continue
visited[state] = True
n_steps = len(trajectory)-t
G = np.sum(discounts[:n_steps] * trajectory[t:, 2])
V[state] = V[state] + alphas[e] * (G - V[state])
V_rec[e] = V.copy()
return V.copy(), V_rec
然后就到了蒙特卡洛算法的主体部分!虽然思路是简单的,但是代码也并不是那么容易理解。
- 先观察这个算法在不同超参数下的表现,可以得到:gamma对于估计V值的影响最大,当gamma=1.0时,蒙特卡洛算法的估计就很不准,但是gamma越小,长序列产生的随机性对于蒙特卡洛算法的影响就越小,从而得到更加准确的估计。其他超参数几乎不起作用。
first_vist=True时,算法收敛更快,误差更小。
我们开始生成折扣和学习率的递降数列。把V初始化为零,因为蒙特卡洛算法无法很准确的估计坑的位置,如果随机初始化会减慢收敛的速度和准确度!
进入for循环,我们先生成一个完整的智能体移动的过程。因为默认给出了最佳策略,所以基本上智能体都能够成功到达终点获得奖励,只是时间不同。因为我们锁定是first_visit,所以专门开辟出一个数组记录到达情况。
然后我们遍历经历数组,这里注意切片的规则:
我们当前要处理的经历下标是t,那么它前面一共有t个元素已经被遍历过了。我们在当前的状态下采取行动之后,最终得到了一个奖励。
所以我们对这些奖励进行加权求和,从现在开始算,之后还有len(trajectory)-t步(包含当前),那么我们取折扣数列的这么多项,两个数列做点乘,就可以得到期望的回报,再从此求出差值。
误差随着迭代次数的变化:

1. TD算法:
\[\Large V_{t+1}(S_t) = V_t(S_t) + \alpha_t \left[ R_{t+1} + \gamma V_t(S_{t+1}) - V_t(S_t) \right]\]采用Temporal Difference算法来估计价值函数V。
其实原理非常简单!王树森在他的教程中已经讲得很清楚了,就是用一个更加逼近真实值的估计来代替观测值,并且据此修正价值函数,最终也能收敛得到真正的价值函数。我们先定义了一个学习率下降的函数,然后定义了训练函数,仍然是重在理解原理。
一般来说,TD算法的表现是优于蒙特卡洛算法的。
def td(pi, env, gamma=0.98, init_alpha=0.5, min_alpha=0.01, alpha_decay_ratio=0.3, n_episodes=5000):
nS = env.observation_space.n
V = np.zeros(nS)
V_track = np.zeros((n_episodes, nS))
alphas = decay_schedule(init_alpha, min_alpha, alpha_decay_ratio, n_episodes)
for e in range(n_episodes):
(state, _), done = env.reset(), False
while not done:
action = pi[state]
next_state, reward, termination, truncation, _ = env.step(action)
done = termination or truncation
td_target = reward + gamma * V[next_state] * (not done)
td_error = td_target - V[state]
V[state] = V[state] + alphas[e] * td_error
state = next_state
V_track[e] = V
return V, V_track
可以看出,我们在迭代的过程中产生了一个新的目标值,即reward + gamma * V[next_state]。它是一个更加准确的对当前状态价值的估计,那么我们就应该进行小幅度的修正。下面给出这样时间差序算法的误差随训练过程的变化:

很明显,训练曲线比蒙特卡罗方法平滑了很多!这才是我们想要的!但是为了担心训练方法过于短视,我们还可以引入这两种方法之间的其他算法。
2. NTD算法:
总体观感不如刚才的TD算法,代码不简洁,收敛的更慢,误差的形状类似于蒙特卡洛算法。
和TD算法类比一下,TD是获取一个真实值之后,就立刻转为不够真实的估计;那么NTD对应的是“N步”之后再转为不准确的估计!我们维护一个长度为n的“经验列表”,再利用下面的公式: \(\Large V_{t+n}(S_t) = V_{t+n-1}(S_t) + \alpha_t \left[ G_{t:t+n} - V_{t+n-1}(S_t) \right]\)
和刚才的TD公式大同小异!
def ntd(pi, env, gamma=0.98, init_alpha=0.5, min_alpha=0.01, alpha_decay_ratio=0.5, n_step=3, n_episodes=5000):
nS = env.observation_space.n
V = np.zeros(nS)
V_track = np.zeros((n_episodes, nS))
alphas = decay_schedule(init_alpha, min_alpha, alpha_decay_ratio, n_episodes)
discounts = np.geomspace(1, pow(gamma, n_step), n_step, endpoint=False)
for e in range(n_episodes):
(state, _), done, path = env.reset(), False, []
while not done or path is not None:
path = path[1:]
while not done and len(path) < n_step:
action = pi[state]
next_state, reward, termination, truncation, _ = env.step(action)
done = termination or truncation
experience = (state, reward, next_state, done)
path.append(experience)
state = next_state
if done:
break
n = len(path)
est_state = path[0][0]
rewards = np.array(path)[:,1]
partial_return = discounts[:n] * rewards
bs_val = (gamma**(n_step))* V[next_state] * (not done)
ntd_target = np.sum(partial_return)+bs_val
ntd_error = ntd_target - V[est_state]
V[est_state] = V[est_state] + alphas[e] * ntd_error
if len(path) == 1 and path[0][3]:
path = None
V_track[e] = V
return V, V_track
但我还是解释一下吧,确保自己理解了。
首先我们还是照常定义了一些基本变量。为了记录模型的改善情况,我们添加了变量V_track。然后进入迭代环节。我们对path列表进行滚动,注意,刚开始的时候path是空列表,切片处理不会报错,仍然会返回空列表!然后,我们就把path这个列表用智能体的经验给填充满。循环结束的时候,要么列表的长度已经等于n_step,要么智能体的在此环境下已经到达终止状态。
记住我们的目标是对path的开始状态估计对应的价值。对照着公式,我们有:更好的估计可以是这几回合的奖励再加上之后期望的奖励。
这个算法还有一个特别奇异的一点,就是它的终止条件。为什么它的终止条件是既done又要path的长度为1?因为:如果长度为3的路径遇到终止情况的话立刻就跳到下一次模拟,那么有些状态就没法被更新,所以我们必须把长度为3的path数组代谢掉,多循环几次,让它的长度为1,确保所有的状态都得到了更新!

值得注意的是,对于训练很多个回合的情况,一般来说应当让学习率下降的快一些,我刚才这样没有调参数直接让模型循环5000次,反而会降低表现,让曲线不是很平稳。就从波动幅度来看,其实刚才的TD算法是最平稳的,表现也非常好。
3. TD-λ算法:
虽然刚才的NTD算法理论上是对蒙特卡洛算法和TD算法的一种改进,但是它还是有很多问题。比如说,你到底应该选择一个什么样的值作为N呢?
于是就有研究者提出了这样的想法:我们把这N步得到的结果加权之后,一股脑地对价值函数进行更新!这就是前向TD(λ)函数所做的。 \(\Large G^\lambda_{t:T} = (1-\lambda) \underbrace{\sum_{n=1}^{T-t-1} \lambda^{n-1} G_{t:t+n}}_{\text{Weighted}} + \lambda^{T-t-1} G_{t:T}\)
\[\Large G_{t:t+n} = R_{t+1} + \dots + \gamma^{n-1} R_{t+n} + \gamma^n V_{t+n-1}(S_{t+n})\]这里重点解释一下这几个公式,只有理解它们是怎么来的,后面的资格迹才能引入的合情合理。首先,我们定义n步回报:用n步加权的准确估计再加上这之后的粗略估计。这个和上面的NTD算法是一脉相承的($\large G_t=G_{t:t+n}$)。然后我们根据这样的n步回报再去定义一个新的量:λ回报。
λ回报的一种最简单的形式就是$\large G^λ_t=(1−λ)\sum {n=1}^{\infin}λ^{n−1}G{t:t+n}$。我们在前面乘上1-λ就是为了起到归一化的作用。
实际上,我们的智能体不可能真正把游戏进行无穷多步,假设游戏进行T步之后就终止了。那么,从t+1到第T-1步我们仍然正常计算加权之后的期望和,但是在最后的第T步,我们直接就使用真正的回报:注意最后一项$\large\lambda^{T-t-1}G_{t:T}$是在求和符号之外的,不会进行归一化,这是为了适应λ=1的情况,这个公式就能正好划归成为蒙特卡罗方法,而λ=0时,我们令0的零次方为1,那么它就成为了时序差分(TD)算法。
但是在实际实现的过程中,λ回报的计算过于复杂,于是又有人研究出了用于实现这种更新的等效方法,那就是使用资格迹。
每次智能体经历一个状态,就会给该状态对应的资格迹加上1。每一个动作之后,资格迹中所有元素都会变成原来的λ倍,也就是经历衰减过程。这样,我们就可以同时对多个状态进行基于λ回报的更新,相当于一个简洁而且完全自动化的过程!
def td_lambda(pi, env, gamma=0.98, init_alpha=0.5, min_alpha=0.01, alpha_decay_ratio=0.3, lambda_=0.3, n_episodes=5000):
nS = env.observation_space.n
V = np.zeros(nS)
V_track = np.zeros((n_episodes, nS))
E = np.zeros(nS)
alphas = decay_schedule(init_alpha, min_alpha, alpha_decay_ratio, n_episodes)
for e in range(n_episodes):
E.fill(0)
(state, _), done = env.reset(), False
while not done:
action = pi[state]
next_state, reward, termination, truncation, _ = env.step(action)
done = termination or truncation
td_target = reward + gamma * V[next_state] * (not done)
td_error = td_target - V[state]
E[state] = E[state] + 1
V = V + alphas[e] * td_error * E
E = gamma * lambda_ * E
state = next_state
V_track[e] = V
return V, V_track

可以看出来,收敛迅速,曲线平稳,是一种好方法,而且代码比较简单!
5. 不知道马尔科夫链,求最优化策略
刚才我们已经能够比较准确地估计一个策略对应的状态价值函数,但是为了优化策略,并且进一步得到最佳的策略,我们可以估计动作价值函数!
0. 蒙特卡罗方法:
换汤不换药。generate_trajectory被稍微改了一下,这样就可以增加随机行动的概率,让智能体能够学习;然后剩下的逻辑和之前的蒙特卡罗方法大同小异。
注意一下这里first_visit和every_visit相对应,两者都能够收敛,但是first_visit收敛更快。如果一个回合中只更新状态一次,受随机性的偏差影响就要小一些。
def generate_trajectory(select_action, Q, epsilon, env, max_steps=200):
done, trajectory = False, []
while not done:
state, _ = env.reset()
for t in range(max_steps):
action = select_action(state, Q, epsilon)
next_state, reward, termination, truncation, _ = env.step(action)
done = termination or truncation
experience = (state, action, reward, next_state, done)
trajectory.append(experience)
if done:
break
state = next_state
if not done:
trajectory = []
return np.array(trajectory, int)
def mc_control(env, gamma=0.98, init_alpha=0.3, min_alpha=0.005, alpha_decay_ratio=0.3, init_epsilon=1.0, min_epsilon=0.1, epsilon_decay_ratio=0.9, n_episodes=12000, max_steps=200, first_visit=True):
nS, nA = env.observation_space.n, env.action_space.n
discounts = np.geomspace(1, pow(gamma, max_steps), max_steps, endpoint=False)
alphas = decay_schedule(init_alpha, min_alpha, alpha_decay_ratio, n_episodes)
epsilons = decay_schedule(init_epsilon, min_epsilon, epsilon_decay_ratio, n_episodes)
pi_track = []
Q = np.zeros((nS, nA), dtype=np.float64)
Q_track = np.zeros((n_episodes, nS, nA), dtype=np.float64)
select_action = lambda state, Q, epsilon: np.argmax(Q[state]) if np.random.random() > epsilon else np.random.randint(len(Q[state]))
for e in range(n_episodes):
trajectory = generate_trajectory(select_action, Q, epsilons[e], env, max_steps)
visited = np.zeros((nS, nA), dtype=np.bool)
for t, (state, action, _, _, _) in enumerate(trajectory):
if visited[state][action] and first_visit:
continue
visited[state][action] = True
n_steps = len(trajectory)-t
G = np.sum(discounts[:n_steps] * trajectory[t:, 2])
Q[state][action] = Q[state][action] + alphas[e] * (G - Q[state][action])
Q_track[e] = Q
pi_track.append(np.argmax(Q, axis=1))
V = np.max(Q, axis=1)
pi = list(np.argmax(Q, axis=1))
return Q, V, pi, Q_track, pi_track
刚开始的变量定义什么之类的根本就不需要关注,我们只是对每一个动作都求预期收益,就可以对真实的Q函数进行优化。

超参数调整为gamma=1.0,然后运行30000个回合,就可以得到最优策略!
在真实项目中不推荐蒙特卡洛算法,因为它采用的是一种“离线学习”方法,在一个回合完全结束之后,才能从经验里面开始学习。
1. SARSA算法:
TD算法的变形。其实代码也是很好理解的。
def sarsa(env, gamma=1.0, init_alpha=0.6, min_alpha=0.01, alpha_decay_ratio=0.5, init_epsilon=1.0, min_epsilon=0.1, epsilon_decay_ratio=0.9, n_episodes=30000):
nS, nA = env.observation_space.n, env.action_space.n
pi_track = []
Q = np.zeros((nS, nA), dtype=np.float64)
Q_track = np.zeros((n_episodes, nS, nA), dtype=np.float64)
select_action = lambda state, Q, epsilon: np.argmax(Q[state]) if np.random.random() > epsilon else np.random.randint(len(Q[state]))
alphas = decay_schedule(init_alpha, min_alpha, alpha_decay_ratio, n_episodes)
epsilons = decay_schedule(init_epsilon, min_epsilon, epsilon_decay_ratio, n_episodes)
for e in range(n_episodes):
(state, _), done = env.reset(), False
action = select_action(state, Q, epsilons[e])
while not done:
next_state, reward, termination, truncation, _ = env.step(action)
done = termination or truncation
next_action = select_action(next_state, Q, epsilons[e])
td_target = reward + gamma * Q[next_state][next_action] * (not done)
td_error = td_target - Q[state][action]
Q[state][action] = Q[state][action] + alphas[e] * td_error
state, action = next_state, next_action
Q_track[e] = Q
pi_track.append(np.argmax(Q, axis=1))
V = np.max(Q, axis=1)
pi = list(np.argmax(Q, axis=1))
return Q, V, pi, Q_track, pi_track
就是表现欠佳,虽然误差能够收缩到0.2,但是智能体的policy还是离最优状态差了一点……或者说两种最优状态基本上都是等价的,没有什么区别。

我个人感觉SARSA算法的曲线还是比较平稳的,应该是更容易收敛。
2. Q-Learning算法:
\[\large \begin{align*} &\text{Start with } Q_0(s,a)\quad\text{for all }s,a,\\ &\text{Get initial state }s,\\ &\text{For }k=1,2,\dots\text{ till convergence:}\nonumber\\ &\quad\text{Sample action }a,\ \text{get next state }s',\\ &\quad\text{If }s'\text{ is terminal:}\nonumber\\ &\qquad\text{target}=R(s,a,s'),\\ &\qquad\text{Sample new initial state }s',\\ &\quad\text{else:}\nonumber\\ &\qquad\text{target}=R(s,a,s')+\gamma\max_{a'}Q_k(s',a'),\\ &\quad Q_{k+1}(s,a)\leftarrow(1-\alpha)Q_k(s,a)+\alpha[\text{target}],\\ &\quad s\leftarrow s'. \end{align*}\]这个算法收敛的要求:如果持续训练,所有状态和动作都要被访问无数次;学习率的总和应该符合下面的规律。 \(\large\begin{align*} \sum_{t=0}^{\infty}\alpha_t(s,a) &= \infty\\ \sum_{t=0}^{\infty}\alpha_t^2(s,a) &< \infty \end{align*}\) 和刚才的SARSA算法其实大同小异。
唯一的区别是,对于下一个状态动作的选择,我们使用贪心算法,而不再引入随机的ε。这会导致如果回合数较少,出现误差反弹的情况,所以回合数需要设置的很大!不过最终智能体可以找到最佳的策略。
def q_learning(env, gamma=0.985, init_alpha=0.5, min_alpha=0.01, alpha_decay_ratio=0.5, init_epsilon=1.0, min_epsilon=0.1, epsilon_decay_ratio=0.9, n_episodes=20000):
nS, nA = env.observation_space.n, env.action_space.n
pi_track = []
Q = np.zeros((nS, nA), dtype=np.float64)
Q_track = np.zeros((n_episodes, nS, nA), dtype=np.float64)
select_action = lambda state, Q, epsilon: np.argmax(Q[state]) if np.random.random() > epsilon else np.random.randint(len(Q[state]))
alphas = decay_schedule(init_alpha, min_alpha, alpha_decay_ratio, n_episodes)
epsilons = decay_schedule(init_epsilon, min_epsilon, epsilon_decay_ratio, n_episodes)
for e in range(n_episodes):
(state, _), done = env.reset(), False
while not done:
action = select_action(state, Q, epsilons[e])
next_state, reward, termination, truncation, _ = env.step(action)
done = termination or truncation
td_target = reward + gamma * Q[next_state].max() * (not done)
td_error = td_target - Q[state][action]
Q[state][action] = Q[state][action] + alphas[e] * td_error
state = next_state
Q_track[e] = Q
pi_track.append(np.argmax(Q, axis=1))
V = np.max(Q, axis=1)
pi = list(np.argmax(Q, axis=1))
return Q, V, pi, Q_track, pi_track

现在看来Q学习算法就已经算得上是一种很自然的算法了。
3. Double-Q-Learning算法:
它针对的是刚才Q-Learning过程中的缺陷:在估测动作之后的预期价值时,总是取最大的那一项,因此就有一个增大误差的趋势!于是Double-Q-Learning应运而生。智能体使用一个Q函数进行奖励的获得和之后的函数值修正,而使用另一个Q函数估计预期的回报,二者分开进行,理论上就能够有效避免偏差被放大。
相对于刚才的算法,原理变化其实不大,也需要通过调高回合次数和降低gamma的值来达到最佳的训练过程。
def double_q_learning(env, gamma=0.985, init_alpha=0.5, min_alpha=0.01, alpha_decay_ratio=0.5, init_epsilon=1.0, min_epsilon=0.1, epsilon_decay_ratio=0.9, n_episodes=30000):
nS, nA = env.observation_space.n, env.action_space.n
pi_track = []
Q1 = np.zeros((nS, nA), dtype=np.float64)
Q2 = np.zeros((nS, nA), dtype=np.float64)
Q_track1 = np.zeros((n_episodes, nS, nA), dtype=np.float64)
Q_track2 = np.zeros((n_episodes, nS, nA), dtype=np.float64)
select_action = lambda state, Q, epsilon: np.argmax(Q[state]) if np.random.random() > epsilon else np.random.randint(len(Q[state]))
alphas = decay_schedule(init_alpha, min_alpha, alpha_decay_ratio, n_episodes)
epsilons = decay_schedule(init_epsilon, min_epsilon, epsilon_decay_ratio, n_episodes)
for e in range(n_episodes):
(state, _), done = env.reset(), False
while not done:
action = select_action(state, (Q1 + Q2)/2., epsilons[e])
next_state, reward, termination, truncation, _ = env.step(action)
done = termination or truncation
if np.random.random() > 0.5:
argmax_Q1 = np.argmax(Q1[next_state])
td_target = reward + gamma * Q2[next_state][argmax_Q1] * (not done)
td_error = td_target - Q1[state][action]
Q1[state][action] = Q1[state][action] + alphas[e] * td_error
else:
argmax_Q2 = np.argmax(Q2[next_state])
td_target = reward + gamma * Q1[next_state][argmax_Q2] * (not done)
td_error = td_target - Q2[state][action]
Q2[state][action] = Q2[state][action] + alphas[e] * td_error
state = next_state
Q_track1[e] = Q1
Q_track2[e] = Q2
pi_track.append(np.argmax((Q1 + Q2)/2., axis=1))
Q = (Q1 + Q2)/2.
V = np.max(Q, axis=1)
pi = list(np.argmax(Q, axis=1))
return Q, V, pi, (Q_track1 + Q_track2)/2., pi_track

4. Sarsa(λ)算法:
相当于TD(λ)与SARSA的杂交版本。
引入了一种叫做替换资格迹的新技术,就是规定所有的资格迹的值都不能超过1。这样做的好处是,如果在那一时刻智能体陷入了状态的死循环,资格迹也不会变得大的离谱,从而有效保证动作价值函数的正常更新。
def sarsa_lambda(env, gamma=1, init_alpha=0.5, min_alpha=0.005, alpha_decay_ratio=0.5, init_epsilon=1.0, min_epsilon=0.1, epsilon_decay_ratio=0.9, lambda_=0.5, replacing_traces=True, n_episodes=30000):
nS, nA = env.observation_space.n, env.action_space.n
pi_track = []
Q = np.zeros((nS, nA), dtype=np.float64)
Q_track = np.zeros((n_episodes, nS, nA), dtype=np.float64)
E = np.zeros((nS, nA), dtype=np.float64)
select_action = lambda state, Q, epsilon: np.argmax(Q[state]) if np.random.random() > epsilon else np.random.randint(len(Q[state]))
alphas = decay_schedule(init_alpha, min_alpha, alpha_decay_ratio, n_episodes)
epsilons = decay_schedule(init_epsilon, min_epsilon, epsilon_decay_ratio, n_episodes)
for e in range(n_episodes):
E.fill(0)
(state, _), done = env.reset(), False
action = select_action(state, Q, epsilons[e])
while not done:
next_state, reward, termination, truncation, _ = env.step(action)
done = termination or truncation
next_action = select_action(next_state, Q, epsilons[e])
td_target = reward + gamma * Q[next_state][next_action] * (not done)
td_error = td_target - Q[state][action]
E[state][action] = E[state][action] + 1
if replacing_traces:
E.clip(0, 1, out=E)
Q = Q + alphas[e] * td_error * E
E = gamma * lambda_ * E
state, action = next_state, next_action
Q_track[e] = Q
pi_track.append(np.argmax(Q, axis=1))
V = np.max(Q, axis=1)
pi = list(np.argmax(Q, axis=1))
return Q, V, pi, Q_track, pi_track

难道是SARSA类算法的通病吗?仍然找不到最优策略!(在第三个格子的移动上产生了分歧)。
5. Q(λ)算法:
能够得到最优策略。简洁性欠佳。
这里对于资格迹的使用也复杂了很多。比如说,第一处让人困惑的地方,就是replacing_traces=True意味着资格迹在遇到新的动作时,会清除在该状态下其他动作的资格迹。我查了半天才知道这就是替换资格迹的定义,主动减小对于旧动作的印象。
而且我们采用的改进就是不要让Q-Learning算法那么贪心,所以如果我们确定某一次行动中,智能体没有选择最优的算法,而是选择去探索其他的算法,那么我们就要清除所有旧动作的痕迹,重新开始!如果就是按照贪心的动作来,那么对于旧动作的记忆才会慢慢淡化而不是一下被抹除。
def q_lambda(env, gamma=0.985, init_alpha=0.5, min_alpha=0.01, alpha_decay_ratio=0.5, init_epsilon=1.0, min_epsilon=0.1, epsilon_decay_ratio=0.9, lambda_=0.5, replacing_traces=True, n_episodes=30000):
nS, nA = env.observation_space.n, env.action_space.n
pi_track = []
Q = np.zeros((nS, nA), dtype=np.float64)
Q_track = np.zeros((n_episodes, nS, nA), dtype=np.float64)
E = np.zeros((nS, nA), dtype=np.float64)
select_action = lambda state, Q, epsilon: np.argmax(Q[state]) if np.random.random() > epsilon else np.random.randint(len(Q[state]))
alphas = decay_schedule(init_alpha, min_alpha, alpha_decay_ratio, n_episodes)
epsilons = decay_schedule(init_epsilon, min_epsilon, epsilon_decay_ratio, n_episodes)
for e in range(n_episodes):
E.fill(0)
(state,_), done = env.reset(), False
action = select_action(state,Q,epsilons[e])
while not done:
next_state, reward, termination, truncation, _ = env.step(action)
done = termination or truncation
next_action = select_action(next_state, Q, epsilons[e])
next_action_is_greedy = Q[next_state][next_action] == Q[next_state].max()
td_target = reward + gamma * Q[next_state].max() * (not done)
td_error = td_target - Q[state][action]
if replacing_traces: E[state].fill(0)
E[state][action] = E[state][action] + 1
Q = Q + alphas[e] * td_error * E
if next_action_is_greedy:
E = gamma * lambda_ * E
else:
E.fill(0)
state, action = next_state, next_action
Q_track[e] = Q
pi_track.append(np.argmax(Q, axis=1))
V = np.max(Q, axis=1)
pi = list(np.argmax(Q, axis=1))
return Q, V, pi, Q_track, pi_track

6. 求最优化策略的过程中,给环境建模
以上的算法都属于无建模类型的强化学习。但是,如果我们已经知道环境是符合马尔科夫条件的,为什么不能尝试用智能体去给环境建模,再像最开始的动态规划算法那样去策划自己的路径呢?这就是下面的基于建模的算法涉及到的。
1. Dyna-Q算法:
它是Q-Learning算法的一种变体。
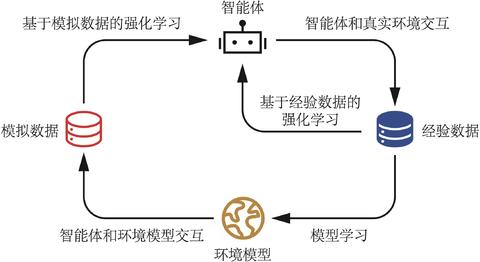
我们首先让智能体根据Q-Learning学几次,然后要求智能体记录自己经过的状态和状态转移过程,来构建出一个越来越准确的环境马尔可夫模型,然后根据超参数n_planning的要求,根据自己的模型来生成模拟数据,并且像对待真实数据一样来执行Q-Learning,从而理论上可以更快、更高效地找到最优策略!
从模型的直观表现上来看,它的训练速度显著慢于其他算法,而且超参数也很难调试。我在windows电脑上能够跑出历史最高分,现在换了一个Apple笔记本,反而就再也跳不出来像下面图中如此卓越的表现了。
再讲几句算法的细节。
- 我们定义了状态转移的计数数组
T_count,还有一个model来记录状态转移的奖励。 - 进入训练的循环之后,我们更新计数器,但是在更新模型数据的时候,我们使用的是一个不太一样的代码:把r_diff除以对应的状态转移次数!其实这相当于一个超参数的简化,可以更快促进模型的收敛,省的我们自己设置一个可变的参数去调整。我记得什么选择这个因子的规则就是:所有因子线性相加是发散的,但是它们的平方和则是收敛的,不知道能不能用在这里解释这个除法。
- 更新完模型之后,我们就是使用正常的Q-Learning方法对动作价值函数进行更新。然后进入规划调整环节,根据超参数的规定,迭代一定次数:
- 如果智能体还没有任何经验,就不要进行任何规划,所以排除
Q.sum()==0的情况!当然,这个语句只是为了防止后面报错:智能体选择一个已经探索过的状态,根据之前的概率分布随机选择一个动作,跳转到下一个状态,得到一个奖励。没错,强化学习的字面意思就体现在这里,明明这些都是智能体生成的模拟数据,我们却把它当作真的一样,强化智能体的经验!
def dyna_q(env, gamma=0.98, init_alpha=0.5, min_alpha=0.01, alpha_decay_ratio=0.5, init_epsilon=1.0, min_epsilon=0.08, epsilon_decay_ratio=0.9, n_planning=3, n_episodes=3000):
nS, nA = env.observation_space.n, env.action_space.n
pi_track = []
Q = np.zeros((nS, nA), dtype=np.float64)
Q_track = np.zeros((n_episodes, nS, nA), dtype=np.float64)
T_count = np.zeros((nS, nA, nS), dtype=int)
R_model = np.zeros((nS, nA, nS), dtype=np.float64)
select_action = lambda state, Q, epsilon: np.argmax(Q[state]) if np.random.random() > epsilon else np.random.randint(len(Q[state]))
alphas = decay_schedule(init_alpha, min_alpha, alpha_decay_ratio, n_episodes)
epsilons = decay_schedule(init_epsilon, min_epsilon, epsilon_decay_ratio, n_episodes)
for e in tqdm(range(n_episodes)):
(state, _), done = env.reset(), False
while not done:
action = select_action(state, Q, epsilons[e])
next_state, reward, termination, truncation, _ = env.step(action)
done = termination or truncation
T_count[state][action][next_state] += 1
r_diff = reward - R_model[state][action][next_state]
R_model[state][action][next_state] += (r_diff / T_count[state][action][next_state])
td_target = reward + gamma * Q[next_state].max() * (not done)
td_error = td_target - Q[state][action]
Q[state][action] = Q[state][action] + alphas[e] * td_error
backup_next_state = next_state
for _ in range(n_planning):
if Q.sum() == 0: break
visited_states = np.where(np.sum(T_count, axis=(1, 2)) > 0)[0]
state = np.random.choice(visited_states)
actions_taken = np.where(np.sum(T_count[state], axis=1) > 0)[0]
action = np.random.choice(actions_taken)
probs = T_count[state][action] / T_count[state][action].sum()
next_state = np.random.choice(np.arange(nS), size=1, p=probs)[0]
reward = R_model[state][action][next_state]
td_target = reward + gamma * Q[next_state].max()
td_error = td_target - Q[state][action]
Q[state][action] = Q[state][action] + alphas[e] * td_error
state = backup_next_state
Q_track[e] = Q
pi_track.append(np.argmax(Q, axis=1))
V = np.max(Q, axis=1)
pi = list(np.argmax(Q, axis=1))
return Q, V, pi, Q_track, pi_track

说实话,这是我第一个看见误差能够逼近0.0的算法,可能是因为frozen lake环境本来就是这么建模的!
2. Trajectory Sampling算法:
因为这个算法和刚才的动态Q学习算法有很多相似之处,所以我就不在乎把整段代码都粘贴下来,其实变的地方只有这么一小段:
它解决的是上一个算法的缺陷,我们在做规划的时候,不想随机的挑选一个状态和一个动作来进行规划,而是要有目的、有针对性地规划!我们挑选当前状态下最有价值的动作进行强化,以此类推。也就是这些修改增加了算法的贪心程度。
def trajectory_sampling(env, gamma=0.985, init_alpha=0.6, min_alpha=0.01, alpha_decay_ratio=0.5,init_epsilon=1.0, min_epsilon=0.1, epsilon_decay_ratio=0.9, max_trajectory_depth=20, n_episodes=3000):
...
for _ in range(max_trajectory_depth):
if Q.sum() == 0: break
# action = select_action(state, Q, epsilons[e])
action = Q[state].argmax()
if not T_count[state][action].sum(): break
probs = T_count[state][action] / T_count[state][action].sum()
next_state = np.random.choice(np.arange(nS), size=1, p=probs)[0]
reward = R_model[state][action][next_state]
td_target = reward + gamma * Q[next_state].max()
td_error = td_target - Q[state][action]
Q[state][action] = Q[state][action] + alphas[e] * td_error
state = next_state
...

可以找到最优策略,但是需要一些超参数的微调。我发现往往误差最低的时候,程序找到的策略反而不是最优的,可能和这个环境有一定的关系。OpenAI的gym库里面有对环境的自动限制,那就是智能体执行动作的动作数不能够超过100,可能就造成了这种影响。
CartPole-v1环境:神经网络与强化学习结合!
终于,我们进行到需要神经网络参与强化学习的环节了!当然,那些用一个函数就能实现整个智能体训练过程的时代已经一去不复返了。
我们无非是用神经网络拟合动作价值函数,原理其实很好理解,但要是落实到代码上,难度其实还是挺大的。所以请听我慢慢道来:
先介绍一下使用的环境。CartPole-v1就是一个平衡车上面连接着一根杆子,你可以对小车施加向左或向右的力,来保持这根杆子在竖直位置上保持平衡,如果小车的位置离屏幕的中心太远,或者杆子离竖直方向的偏离角度超过了12度,程序就立刻终止。杆子保持竖直的每一时刻,智能体都会收到+1的奖励。智能体可以利用的数据有四个:小车的位置;小车的速度;杆子的偏角;杆的顶点的线速度。
我接触到的第一个真正有用的算法就是:遗传算法。
首先,我们随机生成一些游戏的过程,然后看一看智能体在整个过程中积攒的奖励是多少。在所有的回合中,我们选出排名前30%的作为训练集来训练我们的神经网络,然后如此持续下去。
事实上,这个方法虽然非常简单,但是非常管用!一个很简单的神经网络,很简洁的代码就可以实现!细节我放在下面:
from dataclasses import dataclass
import typing as tt
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
HIDDEN_SIZE = 128
BATCH_SIZE = 16
PERCENTILE = 70
class Net(nn.Module):
def __init__(self, obs_size: int, hidden_size: int, n_actions: int):
super(Net, self).__init__()
self.net = nn.Sequential(
nn.Linear(obs_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, n_actions)
)
def forward(self, x: torch.Tensor):
return self.net(x)
@dataclass
class EpisodeStep:
observation: np.ndarray
action: int
@dataclass
class Episode:
reward: float
steps: tt.List[EpisodeStep]
这是代码的第一部分,前面导入什么库我就不说了,然后常量啥的也很容易理解。然后我们定义了一个特别简单的神经网络,只有两层。
然后我们玩一个能够简化代码的dataclass。本质上就是省去了init方法,自定义了一个存储数据的结构。EpisodeStep就是记录每一步智能体检测到的情况,以及作出的动作,然后Episode就是记录一个完整的回合。
def iterate_batches(env: gym.Env, net: Net, batch_size: int):
batch = []
episode_reward = 0.0
episode_steps = []
obs, _ = env.reset()
sm = nn.Softmax(dim=1)
while True:
obs_v = torch.tensor(obs, dtype=torch.float32)
act_probs_v = sm(net(obs_v.unsqueeze(0)))
act_probs = act_probs_v.data.numpy()[0] # convert matrix to vector
action = np.random.choice(len(act_probs), p=act_probs)
next_obs, reward, is_done, is_trunc, _ = env.step(action)
episode_reward += float(reward)
step = EpisodeStep(observation=obs, action=action)
episode_steps.append(step)
if is_done or is_trunc:
e = Episode(reward=episode_reward, steps=episode_steps)
batch.append(e)
episode_reward = 0.0
episode_steps = []
next_obs, _ = env.reset()
if len(batch) == batch_size:
yield batch
batch = []
obs = next_obs
这一段代码只是为了根据现有策略生成指定大小的游戏过程。并且,我们根据结果的softmax值来选择对应的动作。
def filter_batch(batch: tt.List[Episode], percentile: float):
rewards = list(map(lambda s: s.reward, batch))
reward_bound = float(np.percentile(rewards, percentile))
reward_mean = float(np.mean(rewards))
train_obs: tt.List[np.ndarray] = []
train_act: tt.List[int] = []
for episode in batch:
if episode.reward < reward_bound:
continue
train_obs.extend(map(lambda step: step.observation, episode.steps))
train_act.extend(map(lambda step: step.action, episode.steps))
train_obs_v = torch.FloatTensor(np.vstack(train_obs))
train_act_v = torch.LongTensor(train_act)
return train_obs_v, train_act_v, reward_bound, reward_mean
然后我们就进行一个筛选工作,把好的表现作为训练集。
if __name__ == "__main__":
env = gym.make("CartPole-v1")
obs_size = env.observation_space.shape[0]
n_actions = int(env.action_space.n)
net = Net(obs_size, HIDDEN_SIZE, n_actions)
objective = nn.CrossEntropyLoss()
optimizer = optim.Adam(params=net.parameters(), lr=0.01)
for iter_no, batch in enumerate(iterate_batches(env, net, BATCH_SIZE)):
obs_v, acts_v, reward_b, reward_m = filter_batch(batch, PERCENTILE)
optimizer.zero_grad()
action_scores_v = net(obs_v)
loss_v = objective(action_scores_v, acts_v)
loss_v.backward()
optimizer.step()
print("%d: loss=%.3f, reward_mean=%.1f, rw_bound=%.1f" % (iter_no, loss_v.item(), reward_m, reward_b))
if reward_m > 475:
print("Solved!")
break
env = gym.make("CartPole-v1", render_mode='rgb_array')
env = gym.wrappers.RecordVideo(env, video_folder='video0')
state, info = env.reset()
done = False
total_reward = 0
while not done:
action = int(torch.argmax(net(torch.tensor(state))))
next_obs, reward, termination, truncation, _ = env.step(action)
total_reward+=reward
state = next_obs
if termination or truncation:
break
env.close()
这是最终的训练过程。代码真的很简单,如果以后发现还有什么嚼头,那就再进行讨论。反正这是我能够找到的最简洁、逻辑最清楚的仅仅使用神经网络进行拟合函数的强化学习算法。比后面的什么NFQ之类的强多了。
我们尝试的第一个算法是Neural fitted Q iteration,也就是NFQ算法。为了实现对Q函数的近似,我们要构建一个全连接网络,接受4个状态的值作为输入,然后两个输出,分别对应不同动作的价值。
class FCQ(nn.Module):
def __init__(self,
input_dim,
output_dim,
hidden_dims=(32,32),
activation_fc=F.relu):
super(FCQ, self).__init__()
self.activation_fc = activation_fc
self.input_layer = nn.Linear(input_dim, hidden_dims[0])
self.hidden_layers = nn.ModuleList()
for i in range(len(hidden_dims)-1):
hidden_layer = nn.Linear(hidden_dims[i], hidden_dims[i+1])
self.hidden_layers.append(hidden_layer)
self.output_layer = nn.Linear(hidden_dims[-1], output_dim)
def forward(self, state):
x = torch.tensor(state, device='mps', dtype=torch.float32)
x = x.unsqueeze(0)
x = self.activation_fc(self.input_layer(x))
for hidden_layer in self.hidden_layers:
x = self.activation_fc(hidden_layer(x))
x = self.output_layer(x)
return x
在解释一下这里面使用的PyTorch代码。我们使用了ModuleList而不是Sequential,因为这样可以自定义我们进行前向传播的方式,当然也会让代码显得略微麻烦,不过其实两者本质上区别不大。还有,我们通过hidden_dims规定了有两个隐藏层。
在forward方法中,由于可能是numpy的数组传进来,所以我们先进行一步数据类型的转化。然后就是简单的前向传播过程。
那么我们如何优化这个神经网络呢?使用下面这个公式: \(\Large L_i(\theta_i) = \mathbb{E}_{s,a} \left[ \left( q_*(s,a) - Q(s,a; \theta_i) \right)^2 \right]\\ \Large L_i(\theta_i) = \mathbb{E}_{s,a,r,s'} \left[ \left( r + \gamma \max_{a'} Q(s',a'; \theta_i) - Q(s,a; \theta_i) \right)^2 \right]\) 第一个公式是我们理论上想要使用的,但是其实做不到。第二个公式就是我们能够实际使用的,那就是用一个更加贴近真实的值去逼近。 \(\Large \nabla_{\theta_i} L_i(\theta_i) = \mathbb{E}_{s,a,r,s'} \left[ \left( r + \gamma \max_{a'} Q(s', a'; \theta_i) - Q(s, a; \theta_i) \right) \nabla_{\theta_i} Q(s, a; \theta_i) \right]\) 梯度就是这么去计算的。这叫做半梯度法,因为我们的实际估计值也是跟输入有关,所以我们要关闭那一部分的张量的梯度。
转换成代码是这样的:
q_sp = self.model(next_states).detach()
max_future_qs = q_sp.max(axis=1).unsqueeze(1)
max_future_qs *= (~is_terminals)
target_q_s = rewards + self.gamma * max_future_qs
q_sa = self.model(states).gather(1, actions)
额,非常难理解的就是这个gather()的用法。我这里用一个小专题补充:
补充:torch.gather()方法
这篇文章讲的非常好,所以我就部分把这篇文章的思想搬运到这里。
其实我们需要做的就是根据文档走。对于二维表来说,直接用下面简单粗暴的方法就可以秒杀绝大部分的用法:
tensor_0 = tensor([[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11]])
index = torch.tensor([[2, 1, 0]])
tensor_1 = tensor_0.gather(0, index)
print(tensor_1)
# tensor([[9, 7, 5]])
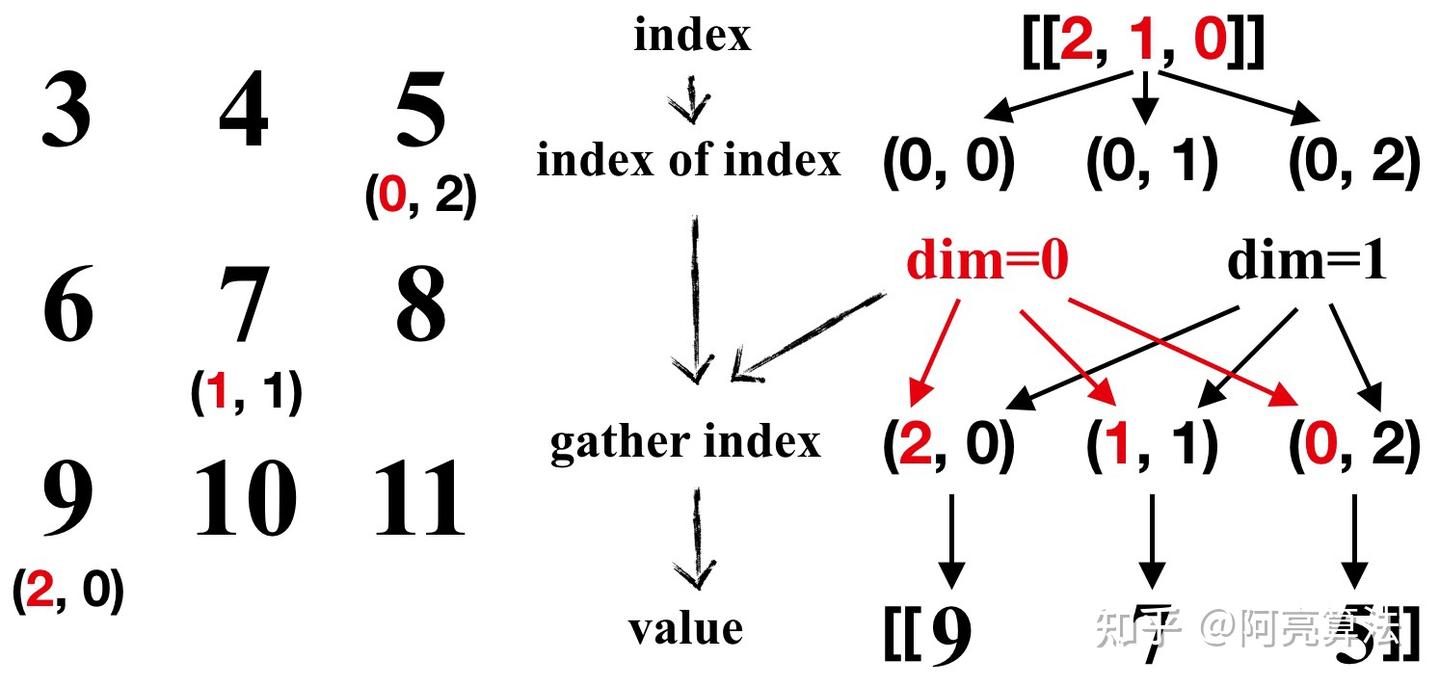
我们要做的:第一步,找到index这个张量,然后把它的索引下标值都写出来。这里是(0, 0), (0, 1), (0, 2)。
第二步,我们把对应的dim维度的值替换成我们index张量中的对应值。在这个例子中,刚才的几个下标就变成了(2, 0), (1, 1), (0, 2)。然后我们就把它原位替换成一个新的张量,就是gather之后的值了!
那么,刚才那段代码中的self.model(states).gather(1, actions)就非常好理解了!很显然,actions是形状为(bs, 1)的二维张量,那么根据上面的规则,我们就可以用这样的表达式把这些不同状态下不同的动作对应的Q值索引出来。
补充:优化神经网络的方法
除了我们熟知的梯度下降之外,还有其他好几种优化器,那么我就在这里大致介绍一下,以后了解了更多信息再进行补充。
- batch gradient descent
- Mini-batch descent
- Stochastic gradient descent
- gradient descent with momentum
- root mean square propagation
- adaptive moment estimation (Adam)
反正没有给代码,我也不用深究这种东西。
然后我发现书里根本就没有给NFQ的完整代码,作者自己开心的训练了一个模型并且展示了NFQ的各种数据,但是我就处于很懵圈的状态,因为我发现掺和上神经网络之后,让模型贴合实际环境的难度大增。
于是我就先看一下后面一章的内容,讲DQN。现在互联网上已经没有讨论NFQ的代码帖子了,因为DQN很明显可以有更大的优点压过前者。在Deep-Q-Network中,第一个显著的改进就是采用Target-Network让训练过程更接近监督学习,而不是让模型追着自己的尾巴。放上公式: \(\Large \nabla_{\theta_i} L_i(\theta_i) = \mathbb{E}_{s,a,r,s'} \left[ \left(r + \gamma \max_{a'} Q(s', a'; \theta^-) - Q(s,a;\theta_i)\right) \nabla_{\theta_i} Q(s,a;\theta_i) \right]\) 我们延迟了价值神经网络的更新,使训练结果更加稳定。
def optimize_model(self, experiences):
states, actions, rewards, next_states, is_terminals = experiences
batch_size = len(is_terminals)
q_sp = self.target_model(next_states).detach()
max_a_q_sp = q_sp.max(1)[0].unsqueeze(1)
max_a_q_sp *= (1 - is_terminals)
target_q_sa = rewards + self.gamma * max_a_q_sp
q_sa = self.online_model(states).gather(1, actions)
td_error = q_sa - target_q_sa
value_loss = td_error.pow(2).mul(0.5).mean()
self.value_optimizer.zero_grad()
value_loss.backward()
self.value_optimizer.step()
def interaction_step(self, state, env):
action = self.training_strategy.select_action(
self.online_model, state)
new_state, reward, is_terminal, _ = env.step(action)
return new_state, is_terminal
def update_network(self):
for target, online in zip(self.target_model.parameters(), self.online_model.parameters()):
target.data.copy_(online.data)
还有一种优化,叫做经验回放,我们从经验池中随机抽取不相关的经验进行学习,从而避免时序相关性,增强模型的泛化能力,对应公式 \(\Large \nabla_{\theta_i} L_i(\theta_i) = \mathbb{E}_{(s,a,r,s') \sim \mathcal{U}(\mathcal{D})} \left[ \left( r + \gamma \max_{a'} Q(s', a'; \theta^-) - Q(s, a; \theta_i) \right) \nabla_{\theta_i} Q(s, a; \theta_i) \right]\)