从Value Iteration到DQN
[TOC]
这本来是我学习Grokking Deep Reinforcement Learning这本书时所做的笔记,但是现在重新看来,发现并没有很好的结构和体系。如今我在学DeepRL BootCamp这个系列的课程,里面的内容更加成体系,所以我打算重新写一份。我先把旧版的笔记发到博客上纪念一下。
我写这份新的笔记的目的是,希望让它能够给整个学习的过程带来清晰的结构,并且让所有希望入门深度强化学习的人都能看懂这份笔记。下面是笔记正文。
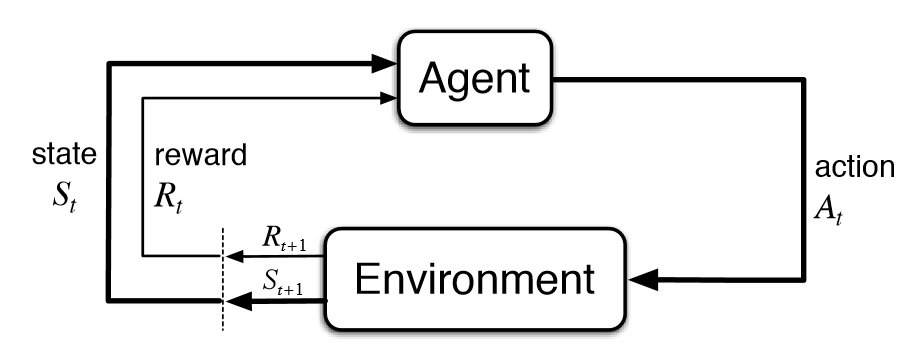
强化学习的本质是马尔可夫决策过程,正如下图所展示的。只不过简单的问题伴随着比较小的状态空间和动作空间,而且它们大多数是离散的;而复杂的问题往往就需要在连续的状态和动作空间中做决策。
第一部分:能够精确求解的问题
在这个部分里,我们使用Frozen Lake环境,小人可以上下左右移动,但是他做出决策之后,只有三分之一的概率能够达到目的,剩下的情况则是向两边滑动。你的目的就是最大化你的奖励。

已知条件:
- 状态转移函数。我们知道在发出指令之后,小人会有多少概率出现在其他相应的格子上。
- 到达第15格时有奖励(+1),但是掉到洞里面会被惩罚(-1)。
状态价值函数的概念
状态价值函数反映的是我们处在某个位置时,如果一直按照某个策略(比如说最优策略)行动,预期获得的奖励是多少。下面给出了最优状态价值函数的定义: \(\begin{align*} V^*(s) &= \max_{\pi}\mathbb{E}\left[\sum_{t=0}^{H}\gamma^{t}R(s_t,a_t,s_{t+1})\;\middle|\;\pi,\;s_0=s\right] \end{align*}\)
对于Frozen Lake这个环境来说,求出$V^*(s)$是非常简单的。如果Horizon=0,那么智能体便没有可以执行的动作,所有状态的奖励都会是零,也就是说 \(\begin{align*} V_0^*(s) &= 0 \quad \forall s \end{align*}\) 那么,如果Horizon=1就有下面的递推公式。这个公式的核心就是在计算:对于每一个我能够采取的动作,在采取动作之后,我都有可能会转移到哪些状态上?转移之后平均能够得到多少奖励?全部计算出来之后,我们选择能提供最大奖励的那个动作。 \(\begin{align*} V_1^*(s) &= \max_{a} \sum_{s'} P(s' \mid s,a)\bigl(R(s,a,s') + \gamma V_0^*(s')\bigr) \end{align*}\) 因为我们每一步迭代只会用到上一步的状态价值函数,所以这个式子是完全可以精确计算出来的!以此类推,我们一直套用这个公式,直到H足够大,就得到了最优的价值函数。下面是完整的迭代算法,可以看出,我们也可以顺便计算出应该在每一步采取的行动是什么——这就是Policy(策略)。 \(\begin{align*} &\text{Start with}\quad V_0^*(s)=0\quad\text{for all }s.\\ &\text{For }k=1,\dots,H:\\ &\quad\text{For all states }s\in\mathcal{S}:\\ &\qquad V_k^*(s)\leftarrow \max_{a}\sum_{s'} P(s'\mid s,a)\Big(R(s,a,s')+\gamma V_{k-1}^*(s')\Big),\\ &\qquad \pi_k^*(s)\leftarrow \arg\max_{a}\sum_{s'} P(s'\mid s,a)\Big(R(s,a,s')+\gamma V_{k-1}^*(s')\Big). \end{align*}\)
价值迭代一定收敛
最后再解释一个理论问题,为什么随着H增大到一定程度之后,我们就相信状态价值函数在各个点的值会收敛?有下面的几点论据:
1. 第H步之后的奖励总和有上限 \(\large \begin{align*} \gamma^{H+1}R(s_{H+1})+\gamma^{H+2}R(s_{H+2})+\dots \le \gamma^{H+1}R_{\max}+\gamma^{H+2}R_{\max}+\dots = \frac{\gamma^{H+1}}{1-\gamma}R_{\max} \end{align*}\) 如果我们前H步都按照最优的方案走,那么最终再获得的总回报也会有上限,而且随着H的增大,这个新增回报的上限趋近于零,所以进行H步迭代随着H的增大,得到的状态价值函数是可以逼近进行无穷多步的状态价值函数。
这个结论的重要意义在于,如果随着H增大回报没有上限,那么函数发散,就不存在所谓状态价值函数这回事!
2. 用不同的方法初始化状态价值函数,会得到同样的结果
除此之外,我们还宣称,不管前面怎么初始化状态价值函数,它最终都会收敛到一套正确的值上。下面给出正式的证明。
我们先定义$|U|$是矩阵U里面绝对值最大的元素。假设我们有两套状态价值函数的估计值U和V,经过一步更新之后,我们得到了TU和TV。现在我们计算TU-TV: \((TU)(s) = \max_a \Big[ R(s,a) + \gamma \sum_{s'} P(s'|s,a)\, U(s') \Big]\) 根据最大值不等式$|\max_a f(a) - \max_a g(a)| \leq \max_a |f(a) - g(a)|$,对两式相减有 \((TU)(s)-(TV)(s)\leq \max_a\; \gamma \Big|\sum_{s'} P(s'|s,a)\big[U(s') - V(s')\big]\Big|\) 利用绝对值不等式进一步缩放 \(\leq \max_a\; \gamma \sum_{s'} P(s'|s,a)\,|U(s') - V(s')|\) 然后我们发现,$|U(s’) - V(s’)|$对于每一个状态都会小于等于$|U-V|$,所以我们直接进行替换,得到对于每一个状态,两个状态价值函数的估计的差距都会至少是原来的$\gamma$倍。所以说,下面的不等式成立: \(\|TU-TV\| \leq \gamma \|U-V\|\) 我们通过这个结论证明了价值迭代只有一个不动点,而且每次操作都会让状态价值函数更加接近这个不动点!
3. 更新足够小时,离最优状态价值函数的距离也会足够小
有了这个定理,我们如果把U、V换成同一个状态价值函数在一次迭代时的前后版本,那么有 \(\|V_{i+1} - V^*\| \leq \gamma\epsilon + \gamma^2\epsilon + \gamma^3\epsilon + \cdots = \frac{\gamma\epsilon}{1-\gamma}\) 这基本上就证明了随机初始化状态价值函数也可以收敛,而且在更新足够小的时候,里面的每个值离最终值的差距也会足够小。
实现价值迭代
我们将用Gymnasium库来实现上面的价值迭代算法。但是我们并不是照抄公式,仔细观察可以发现我们其实每次迭代都相当于计算了一遍完整的动作价值函数。这样直接存储动作价值函数的话,可以避免很多复杂的代码逻辑。
import gymnasium as gym
import numpy as np
env = gym.make('FrozenLake-v1')
def value_iteration(P, gamma=1.0, theta=1e-10):
V = np.zeros(len(P))
for i in range(10):
Q = np.zeros((len(P), len(P[0])))
for s in range(len(P)):
for a in range(len(P[s])):
for prob, next_state, reward, done in P[s][a]:
Q[s][a] += prob * (reward + gamma * V[next_state] * (not done))
if np.max(np.abs(V - np.max(Q, axis=1))) < theta:
break
V = np.max(Q, axis=1)
pi = dict(zip(range(len(P)), np.argmax(Q, axis=1)))
return V, pi
value_iteration(env.unwrapped.P, 0.99).reshape(4, 4)
除了Value Iteration,我们也可以直接对Q函数进行迭代,方法类似,我直接写公式,代码就不写了: \(\begin{align*} Q^{*}_{k+1}(s,a) &\leftarrow \sum_{s'} P(s' \mid s,a)\bigl(R(s,a,s') + \gamma \max_{a'} Q^{*}_{k}(s',a')\bigr) \end{align*}\)
策略迭代
这是和上面所讲述的价值迭代平行的一种算法。我们先随机生成一种策略,然后通过计算这种策略的状态价值函数,来评估这套策略,再一步一步的改进。
Policy Evaluation: **除了没有max在公式里面,其他的大同小异。 \(\begin{align*} V^{\pi_k}_{i+1}(s) &\leftarrow \sum_{s'} P\big(s' \mid s, \pi_k(s)\big)\big[ R\big(s,\pi_k(s),s'\big) + \gamma V^{\pi_k}_i(s') \big] \end{align*}\) **Policy Iteration: 只看一步。 \(\begin{align*} \pi_{k+1}(s) &\leftarrow \arg\max_a \sum_{s'} P(s' \mid s,a)\big[ R(s,a,s') + \gamma V^{\pi_k}(s')\big] \end{align*}\) 接下来看代码。
def policy_evaluation(pi, P, gamma=1.0, theta=1e-10):
prev_V = np.random.random(len(P)) # 16 states in frozen lake env
while True:
V = np.zeros(len(P)) # will be updated shortly after
for s in range(len(P)):
for prob, next_state, reward, done in P[s][pi[s]]:
V[s] += prob * (reward + gamma * prev_V[next_state] * (not done))
if np.max(np.abs(prev_V - V)) < theta:
break
prev_V = V.copy()
return V
def policy_improvement(V, P, gamma=1.0):
Q = np.zeros((len(P), len(P[0])), dtype=np.float64)
# the zeros will be filled out later
for s in range(len(P)):
for a in range(len(P[s])): # for every action in every state
for prob, next_state, reward, done in P[s][a]: # only iterates once
Q[s][a] += prob * (reward + gamma * V[next_state] * (not done))
new_pi = dict(zip(range(len(P)), np.argmax(Q, axis=1)))
return new_pi
第二部分:基于采样的近似方法与函数拟合
很显然,我们在真正的游戏环境中时,不可能知道状态与状态之间的转移概率。
Q-Learning
把动作价值函数的定义改写成期望的形式,就可以得到下面的式子。 \(\begin{align*} Q_{k+1} &\leftarrow \mathbb{E}_{s'\sim P(s'\mid s,a)}\left[ R(s,a,s') + \gamma \max_{a'} Q_k(s',a') \right] \end{align*}\) 这个期望没有办法准确求解,但是我们可以通过在游戏中采样的方法来逼近,这就是Q学习!比如说,我们在某个状态下采取了某个动作,然后转移到了一个新的状态——这就是采样。我们在这个采样下,可以得到关于未来获得奖励的一个新的估计,然后拿这个估计去更新我们原先的动作价值函数。
算法如下: \(\begin{align*} &\text{Start with } Q_0(s,a)\ \text{for all } s,a.\\ &\text{Get initial state } s.\\ &\text{For } k=1,2,\dots \text{ till convergence:}\\ &\quad\text{Sample action } a,\ \text{get next state } s'.\\ &\quad\text{If } s' \text{ is terminal:}\\ &\qquad\text{target} \;=\; R(s,a,s')\\ &\qquad\text{Sample new initial state } s'.\\ &\quad\text{else:}\\ &\qquad\text{target} \;=\; R(s,a,s') + \gamma \max_{a'} Q_k(s',a')\\ &\quad Q_{k+1}(s,a) \;\leftarrow\; (1-\alpha)Q_k(s,a) + \alpha\,[\text{target}]\\ &\quad s \;\leftarrow\; s' \end{align*}\) 这个算法里有了一个自由度,那就是对动作的采样。我们可以让智能体选择自己估计更有利的动作,但是也需要适当的让智能体对不同的动作有足够多的尝试,也就是“探索”。这里我们一般采取的策略就是epsilon greedy,那就是模型只有一定概率是贪心的,剩下时间随机做出行动。
Q-Learning能够收敛的条件:
- 探索足够多,最终的学习率足够小,同时学习率不能减小的太快。
- 如果时间无限,所有的状态和所有的动作都会被执行无数次。
- 不同episode的学习率符合下面的规律:
把代码放过来:
def q_learning(env, gamma=0.985, init_alpha=0.5, min_alpha=0.01, alpha_decay_ratio=0.5, init_epsilon=1.0, min_epsilon=0.1, epsilon_decay_ratio=0.9, n_episodes=20000):
nS, nA = env.observation_space.n, env.action_space.n
pi_track = []
Q = np.zeros((nS, nA), dtype=np.float64)
Q_track = np.zeros((n_episodes, nS, nA), dtype=np.float64)
select_action = lambda state, Q, epsilon: np.argmax(Q[state]) if np.random.random() > epsilon else np.random.randint(len(Q[state]))
alphas = decay_schedule(init_alpha, min_alpha, alpha_decay_ratio, n_episodes)
epsilons = decay_schedule(init_epsilon, min_epsilon, epsilon_decay_ratio, n_episodes)
for e in range(n_episodes):
(state, _), done = env.reset(), False
while not done:
action = select_action(state, Q, epsilons[e])
next_state, reward, termination, truncation, _ = env.step(action)
done = termination or truncation
td_target = reward + gamma * Q[next_state].max() * (not done)
td_error = td_target - Q[state][action]
Q[state][action] = Q[state][action] + alphas[e] * td_error
state = next_state
Q_track[e] = Q
pi_track.append(np.argmax(Q, axis=1))
V = np.max(Q, axis=1)
pi = list(np.argmax(Q, axis=1))
return Q, V, pi, Q_track, pi_track
除了上面对离散环境学习的Q-Learning算法,我们也可以设计一个神经网络去拟合动作价值函数。但问题是,我们追逐的目标在训练过程中会不断变化,而且在一个游戏内部,智能体得到的经验会存在很大的相关性,如果按照传统的方法进行训练,模型会很难收敛。为了解决这个问题,我们引入下一个网络架构和相应变体:DQN。
DQN
引入两个技巧,这对于DQN的收敛至关重要:
- 经验回放,每一步都从过去的经验中随机抽取一个经验来进行回放。
- 目标网络,用另一套神经网络来估计动作价值函数来作为目标值,可以稳定训练的过程。
算法流程如下。 \(\begin{align*} &\text{Initialize replay memory }D\text{ to capacity }N\\ &\text{Initialize action-value function }Q\text{ with random weights }\theta\\ &\text{Initialize target action-value function }\hat Q\text{ with weights }\theta^-=\theta\\[6pt] &\textbf{For episode }=1,M\textbf{ do}\\ &\qquad \text{Initialize sequence }s_1=\{x_1\}\text{ and preprocessed sequence }\phi_1=\phi(s_1)\\ &\qquad \textbf{For }t=1,T\textbf{ do}\\ &\qquad\qquad \text{With probability }\varepsilon\text{ select a random action }a_t\\ &\qquad\qquad \text{otherwise select }a_t=\arg\max_a Q(\phi(s_t),a;\theta)\\ &\qquad\qquad \text{Execute action }a_t\text{ in emulator and observe reward }r_t\text{ and image }x_{t+1}\\ &\qquad\qquad \text{Set }s_{t+1}=s_t,a_t,x_{t+1}\text{ and preprocess }\phi_{t+1}=\phi(s_{t+1})\\ &\qquad\qquad \text{Store transition }(\phi_t,a_t,r_t,\phi_{t+1})\text{ in }D\\ &\qquad\qquad \text{Sample random minibatch of transitions }(\phi_j,a_j,r_j,\phi_{j+1})\text{ from }D\\ &\qquad\qquad \text{Set }y_j=\begin{cases} r_j & \text{if episode terminates at step }j+1,\\[4pt] r_j+\gamma\max_{a'}\hat Q(\phi_{j+1},a';\theta^-) & \text{otherwise} \end{cases}\\ &\qquad\qquad \text{Perform a gradient descent step on }(y_j-Q(\phi_j,a_j;\theta))^2\text{ w.r.t. }\theta\\ &\qquad\qquad \text{Every }C\text{ steps reset }\hat Q=Q\\ &\qquad \textbf{End For}\\ &\textbf{End For} \end{align*}\) 接下来我来介绍如何用DQN来解决CartPole-v1环境。不过效果不会很好,因为DQN是一种很复杂的架构,解决简单问题反而会力不从心,但是代码的重点是介绍如何写出一个DQN。这里点出第一段代码的几个细节:
- 神经网络在第一层一定要拓展出足够多的信息,从4个神经元直接对应到128个神经元;
- 目标网络在最开始只能使用
deepcopy()复制,之后再用load_state_dict(); - 经验回放最好设置的大一些,否则就会很快出现灾难性遗忘。
- 推荐使用
RMSprop作为优化器。
dqn = nn.Sequential(
nn.Linear(4, 128), nn.ReLU(),
nn.Linear(128, 128), nn.ReLU(),
nn.Linear(128, 2)
)
target_network = copy.deepcopy(dqn)
episodes = 5000
epsilon = np.concatenate([np.geomspace(1, 0.01, 2000), np.full(3000, 0.01)])
D = deque(maxlen=100000)
gamma = 0.99
opt = torch.optim.RMSprop(dqn.parameters(), 1e-3)
recent_rewards = []
- 在把状态从
ndarray转换成张量的时候用torch.float32格式,防止损失精度。 - 使用$\epsilon-Greedy$算法来选择动作。
steps = 0
for i in range(episodes):
done = False
state, _ = env.reset()
state = torch.tensor(state, dtype=torch.float32)
total_rewards = 0
while not done:
steps += 1
action_values = dqn(state)
if random.random() > epsilon[i]:
action = action_values.argmax().item()
else:
action = random.randint(0, 1)
- 关于如何给智能体添加经验,我和Claude的意见产生了分歧。Claude认为经验的最后一项(代表回合是否结束)应该只用termination而不是done,原因是在真到达500回合的时候,程序被截断了,如果和termination做同样的处理,那么其实就相当于在隐性的惩罚智能体。我觉得这两个没有区别,因为被截断也意味着智能体无法获得更多的奖励。在实际测试的过程中,这两种方法几乎没有区别。
next_state, reward, termination, truncation, info = env.step(action)
next_state = torch.tensor(next_state, dtype=torch.float32)
done = termination or truncation
D.append((state, action, reward, next_state, termination))
total_rewards += reward
if len(D) <= 128: continue
sampled = random.sample(D, 128)
states, actions, rewards, next_states, dones = list(zip(*sampled))
states = torch.stack(states)
next_states = torch.stack(next_states)
actions = torch.tensor(actions)
rewards = torch.tensor(rewards)
dones = torch.tensor(dones).float()
- 如何更新神经网络?
我们目前用的方法是直接套公式
\(y_j = r_j + \gamma \max_{a'} \hat{Q}(\phi_{j+1}, a'; \theta^-)\)
但问题是这会让目标网络同时做两件事:选择要做的动作,还有评估自己做的动作好不好。因为后面还有max操作,会让模型估计的Q值整体偏高,不利于训练的稳定性。所以引入Double DQN方法,改成用原本的DQN来选择动作,目标网络只能评估:
\(y_j = r_j + \gamma \hat{Q}\!\left(\phi_{j+1},\; \arg\max_{a'} Q(\phi_{j+1}, a'; \theta);\; \theta^-\right)\)
接下来分别展示两段代码。原先的:
with torch.no_grad():
targets = rewards + (1-dones)*gamma*target_network(next_states).max(axis=1)[0]
loss = F.smooth_l1_loss(dqn(states).gather(1, actions.unsqueeze(1)).squeeze(1), targets)
现在的:(繁琐了一点)
with torch.no_grad():
best_actions = dqn(next_states).argmax(axis=1)
target_q_values = target_network(next_states)
targets = rewards + (1-dones)*gamma*target_q_values.gather(1, best_actions.unsqueeze(1)).squeeze(1)
loss = F.smooth_l1_loss(dqn(states).gather(1, actions.unsqueeze(1)).squeeze(1), targets)
剩下的代码就很容易明白了,无非就是更新参数,记录模型表现。
loss.backward()
opt.step()
opt.zero_grad()
if steps % 1000 == 0: target_network.load_state_dict(dqn.state_dict())
state = next_state
recent_rewards.append(total_rewards)
if i%100 == 0:
print(np.mean(recent_rewards[-100:]))